Ledge、ウェブライダー、SPJ の共同研究プロジェクトとして始まり、2017年12月12日のプレスリリースから約4ヶ月。
本取組におけるさまざまな試行錯誤の中からこの度「ディープラーニング利用・機械学習による誤字脱字検出機能」が、ウェブライダー提供の 推敲・校閲支援ツール『文賢(ブンケン)』へ搭載・公開されました。
搭載された誤字脱字検出モデルの概要
今回、さまざまな試行錯誤がありましたが、現段階では以下のようなアプローチを採用しました。
ディープラーニングならびに自然言語処理の技術を誤字脱字検出に活用し、実際の『文賢』ツールに組み込まれた形となっています。
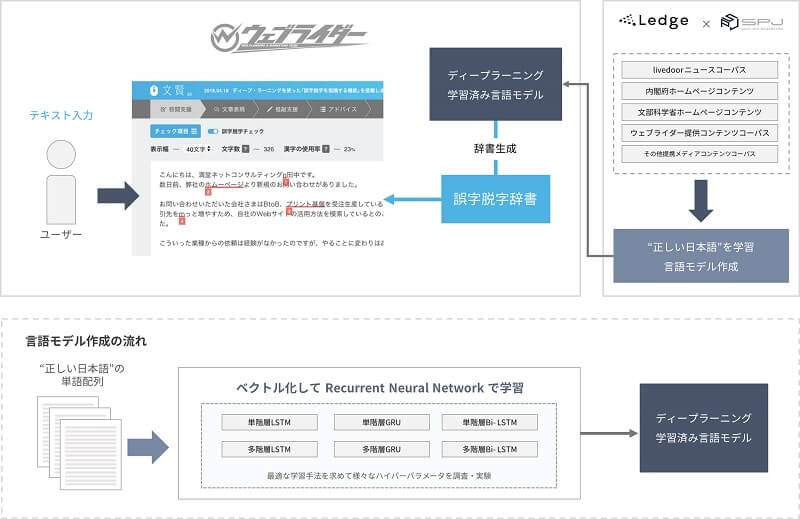
・大量のコーパスからRNN言語モデルを作成。誤字検出に最適な複数のハイパーパラメータを探索
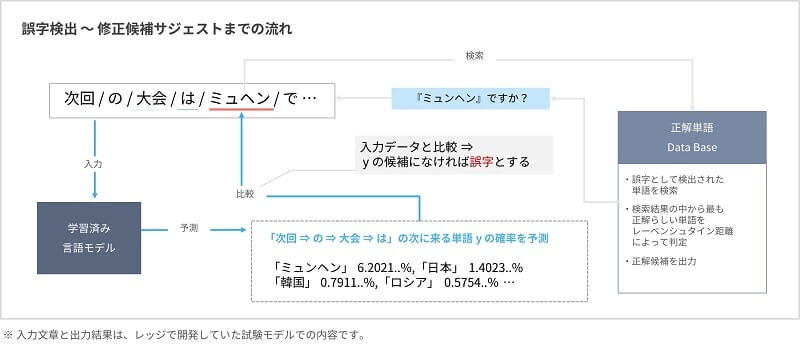
・作成された学習済み言語モデルによる単語の予測と、入力文章との比較
・誤字として検出された単語をもとに、レーベンシュタイン距離による正解らしい単語のサジェストを実行
今回はまだ第一段のリリース。現時点では全ての誤字・脱字を完璧に検出するというわけではありませんが、これまでの共同研究成果から見えてきた更なる改善点に向き合い、今後も更にその精度を進化させていく予定です。
誤字・脱字検出モデルが利用するデータについて
なお、今回リリースされた文賢「誤字脱字チェック機能」においては、株式会社ウェブライダー・株式会社レッジの著作データ、ならびに下記データ(の一部)が学習時の教師データとして利用されています。
- livedoor ニュースコーパス (準拠ライセンス:CC BYND2.1)
- 内閣府ホームページコンテンツ(準拠ライセンス:CC BY 4.0)
- 文部科学省ホームページコンテンツ(準拠ライセンス:CC BY 4.0)
- ウェブライダー提供コンテンツコーパス
- その他提携メディアコンテンツコーパス