※サンプル・コード掲載
あらすじ
「フルーツの画像を判別するモデルを作ってくれませんか?」
と言われた時に、どのようにモデルを作りますか?
ディープラーニングで画像分類を行う場合、通常畳み込みニューラルネットワークという学習手法を使いますが、画像の枚数によっては数週間程度がかかってしまいます。
また、学習に使用する画像の枚数も大量に用意しないといけません。
では、短時間・少ない画像から画像を分類するモデルを作るにはどうすればよいでしょうか。
その解決策として、画像分類でよく使われているfine tuningという手法をご紹介します。
今回はkeras2.0を使ってサンプルコードを書いて行きます。
*keras = Pythonで書かれたニューラルネットワークライブラリ。裏側でtheanoやtensorflowが使用可能。
fine tuning(転移学習)とは?
既に学習済みのモデルを転用して、新たなモデルを生成する方法です。
つまり、他の画像データを使って学習されたモデルを使うことによって、新たに作るモデルは少ないデータ・学習量でモデルを生成することが可能となります。
「他の画像データを使った学習モデルは、学習する時に定義した出力を得るためにしか使えないんじゃないの?」と思うかもしれません。
しかし、大量の画像から大量のカテゴリに分類したネットワークの上層の部分はある程度同じようなフィルタになるということが分かっています。
また、学習済みのモデルの層では画像の特徴を得る層と画像の分類を行う層があります。
その分類を行う層は取ってしまい、特徴を得る層だけもらって、新たなモデルを生成するというわけです。
VGG16: ニューラルネットワークの代表的モデル
ImageNetの120万枚の画像を1000カテゴリに分類した畳み込みニューラルネットワークの代表的なモデルでVGG16というものがあります。
このモデルをfine tuningして学習を行うとその1,000カテゴリ以外の物も簡単に分類出来るようになります。
※ただし注意点として、元々学習で使われた画像と、今回分類しようとしている画像が全然似ていない場合は特徴がそのまま使えない可能性があります。
その場合は、学習データの量もある程度は必要になり、学習に時間もかかります。
転移学習のやり方はいくつかあり、ネットワークのどの層までをtrainingで重みを更新するか、つまりどの層を凍結してtrainingを行うかによって変わってきます。
今回は、全結合層のみ変更し、それ以外の層は全て凍結(重みの更新を行わない)する方法と、VGG16の一部の畳み込み層を学習する方法を試したいと思います。
環境構築
python3を使用します。また、今回はkerasのbackgroundの機械学習ライブラリとしてtheanoを使います。
keras、theanoのインストールは下記を参照して下さい。
https://keras.io/ja/#_2
また、このプログラムはpillowを必要とするため、事前にインストールしておきます。
pip install pillow画像の収集
まずは画像を用意する必要があります。
その辺でダウンロードできる画像分類用コーパスを使ってもいいですが、今回は色々なパターンを試せるようにBIng Seach APIを使って画像を拾ってくることにしました。
def get_bing_image(query,offset=0,count = 150):
url = 'https://api.cognitive.microsoft.com/bing/v5.0/images/search'
headers = {'Ocp-Apim-Subscription-Key': '{key}','Content-Type':'multipart/form-data'}
res = requests.get(url,{'q':query,'count':count,offset:offset},headers=headers)
res = json.loads(res.text)
return res['value']
フィルタで人物や人物の顔のみ等の指定も出来るので便利です。
今回はリンゴ、トマト、いちごの3つのカテゴリで分類してみたいと思います。
ダウンロードした画像を下記のようなフォルダ構成で配置します。

全結合層のみ学習するモデル
VGG16の層は更新せず、新たにくっつけた層のみ学習します。
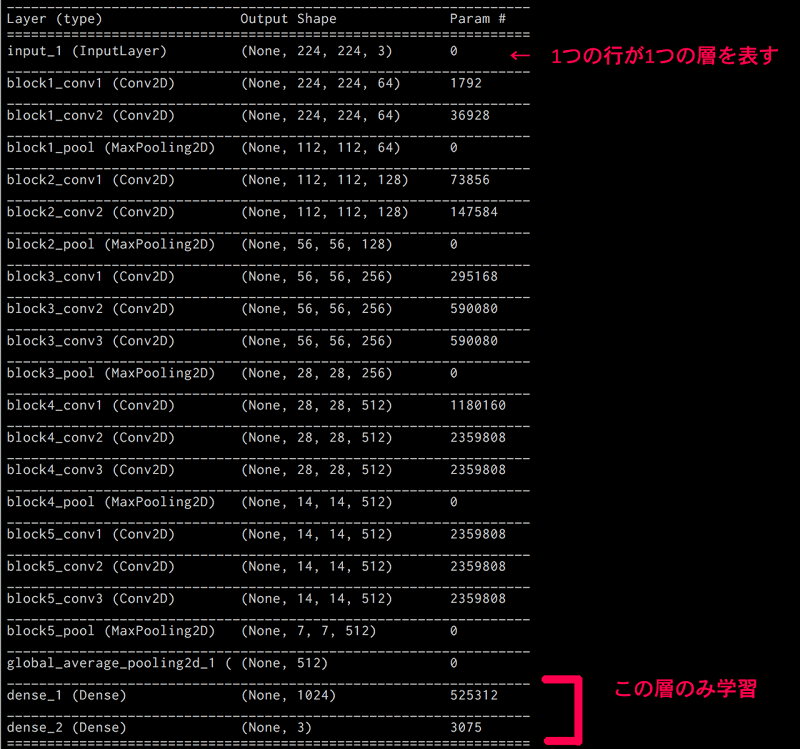
モデルを定義・学習させるコード
実際にモデルを定義・学習させるコードは下記のようになります。
import os.path,sys
sys.path.append(os.path.abspath(os.path.dirname(__file__))+'/../../')
os.environ['KERAS_BACKEND'] = 'theano'
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D,Input
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
import keras.callbacks
N_CATEGORIES = 3
IMAGE_SIZE = 224
BATCH_SIZE = 16
NUM_TRAINING = 1600
NUM_VALIDATION = 400
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
base_model = VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(N_CATEGORIES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers:
layer.trainable = False
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
rotation_range=10)
test_datagen = ImageDataGenerator(
rescale=1.0 / 255,
)
train_generator = train_datagen.flow_from_directory(
'images/train',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
validation_generator = test_datagen.flow_from_directory(
'images/validation',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
hist = model.fit_generator(train_generator,
steps_per_epoch=NUM_TRAINING//BATCH_SIZE,
epochs=50,
verbose=1,
validation_data=validation_generator,
validation_steps=NUM_VALIDATION//BATCH_SIZE,
)
model.save('fruits.hdf5')
NUM_TRAINING = 1600
NUM_VALIDATION = 400
ここでトレーニング及び評価に使う画像の枚数をセットします。
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
base_model = VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
ここではインプットを画像サイズx画像サイズxチャンネル数(RGB)として定義します。
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(N_CATEGORIES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
新たな層を追加しています。
最終的に、今回は3つのクラス分けなので、N_CATEGORIES(=3)の分類を行うモデルとしています。
model.summary()
ネットワークの構造を出力します。
VGG16の構造に加え、最後に層が追加されている事がわかるかと思います。
_________________________________________________________________
global_average_pooling2d_1 ( (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 1024) 525312
_________________________________________________________________
dense_2 (Dense) (None, 3) 3075
_________________________________________________________________
for layer in base_model.layers:
layer.trainable = False
ここでVGG16の全層の重みを固定しています。
つまり、VGG16側の層の重みは学習時に変更されません。
datagen = ImageDataGenerator(rescale=1. / 255)
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
rotation_range=10)
train_generator = train_datagen.flow_from_directory(
'images/train',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
ImageDataGeneratorは与えた画像からズーム、回転、反転などを行って画像のパターンを自動的に増やしてくれます。
これにより画像のパターンを自動的に増やすことが出来る事に加え、画像はいくらでも生成してくれるので枚数の調整も可能です。
今回は多値分類を行うので、以下の様にします。
class_mode=’categorical’
それぞれのパラメータの詳細の意味は下記をご参照下さい。
https://keras.io/ja/preprocessing/image/
hist = model.fit_generator(train_generator,
steps_per_epoch=NUM_TRAINING//BATCH_SIZE,
epochs=30,
verbose=1,
validation_data=validation_generator,
validation_steps=NUM_VALIDATION//BATCH_SIZE
)
fit_generatorはImageDataGeneratorのインスタンスを受け取り、モデルを学習するメソッドです。
このコードによって、モデルの学習にtraning_generatorが使われ、精度の評価にvalidation_generatorが使われます。
実行結果
実際に実行して学習を行うと下記の様な結果が出てくると思います。
Epoch 50/50
25/25 [==============================] - 307s - loss: 0.6588 - acc: 0.8266 - val_loss: 0.5579 - val_acc: 0.9070
評価セットの精度はval_accで確認できます。この場合は90.25%ということです。
9割の精度で分類出来ているということなので、まずまずの結果でしょうか。
一部の層だけ固定して学習させる方法
次に、すべての層を固定するのではなく、一部の層だけ固定して学習してみましょう。
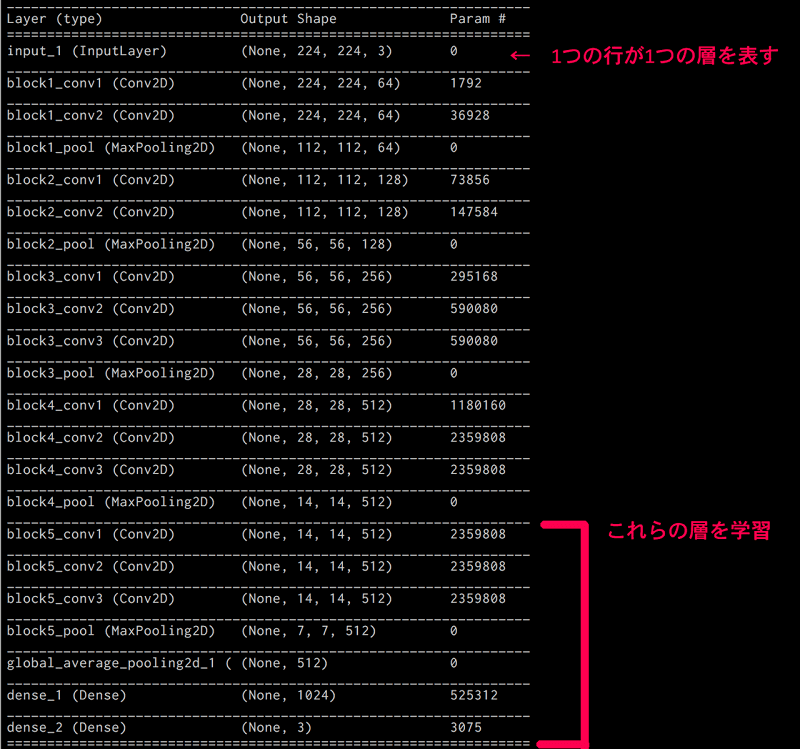
VGG16の最後の畳み込み層は学習されるように、コードを一部書き換えます。
for layer in base_model.layers:
layer.trainable = False
この部分を下記のように変更します。上から15番目の層までは固定するということになります。
for layer in base_model.layers[:15]:
layer.trainable = False
これだけで準備完了ですので、再度実行してみましょう。
実行結果
私が集めたフルーツの画像だとこのようになりました。
![]()
99.7%の精度が出ていますね!
全層固定した時よりも良い結果が出ていることがわかります。
ただ、学習時間も7,8倍になってしまっています。
精度と学習時間はトレードオフの関係なので、用途によって適切な方法を選択することが必要です。