あらすじ
この記事は、私が行ったUdacity(Eラーニング)での自動運転車開発プロジェクトにおいてディープラーニングを応用した道路標識認識実験について書いたものです。
自動運転車にとって交通ルールを理解するための道路標識の読み取りやその解釈は非常に重要なことです。
ディープラーニング・ニューラルネットワークや畳み込みニューラルネットワークは、GPUの発展の結果、過去10年の間に有力な画像分類方法として現れました。
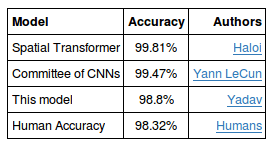
このプロジェクトではドイツの道路標識認識実験において98.8%の精度を出した方法について考察します。
参考として以下は、他の論文で書かれたモデル精度と人間の精度になります。
要約
- 探索的データ分析
- データ・オーグメンテーションとプリ・プロセッシング
- モデル・アーキテクチャ
- トレーニング
- 標識識別テストのデータにおけるモデル・パフォーマンスと未知のデータにおけるモデル・パフォーマンス
- 結論
探索的データ分析
まずドイツの道路標識は以下のように様々なもので構成されています。

さらに各標識は適切な箇所(例えば30の標識は高速道路では見られない)にだけ設置されていると考えられるため、各標識の数には差異があります。
このデータセットの中で最も多く現れる標識は30キロ毎時の標識でした。
また、新たな標識を観測する事前確率は、データ中の発生率に反映されるため相対的な標識の数は変えません。
画像の相対比率は変わらないので、仮にモデルが不確かな2つであった場合、より頻出している標識の方へ予測を偏らせます。
データ・オーグメンテーションと、プリ・プロセッシング
データ・オーグメンテーション
ディープ・ニューラルネットワークの大きな限界は、数え切れないほどのパラメーターが可能になることによって、それを合致させるには膨大な量のデータセットが求められることです。
しかしながら、それがいつも出来るとは限りません。
このようなケースでは、データ・オーグメンテーションを使って追加のトレーニング・サンプルを作り出すことが可能です。
画像にアファイン変換を適用することによって追加のデータサンプルを作ります。
アフィン変換は、線の平行度を変更しない変換、すなわち、マトリックス上の線形動作として表すことができます。
特に使用するのは回転、切り取りと平行移動で、標識を異なる角度や異なる距離から見た時の画像の変化をシミュレーションすることができます。
下の図はオリジナルの画像とそれを元に生み出された画像です。


オーギュメンテーションの詳細説明とコードはこちら。
プリ・プロセッシング
まずは輝度の正規化によって多様な光による画像の変化を取り除き、その後、画像を下の図のように変換します。

強度値(intensity values)の差を-.5から.5の間に納める様にします。
モデル・アーキテクチャ
下の図は我々が使用するモデル・アーキテクチャーで、いくつかの異なるアーキテクチャーを試した上でこの形にたどり着きました。

上記のモデルの最初のモジュールは3つの1X1フィルターを含んでいます。
これらのフィルターはカラーマップを変更する効果を持っており、殆どのアプリケーションではカラーマップの変更によってパフォーマンスは大幅に改善します。
しかしながら、異なるアプリケーションに最適なカラーマップは何か明らかではありません。
そのため、3つの1X1フィルターを使うことでネットワーク自体が最適なカラーマップを選ぶことになります。
次の3つのモジュールはマックスプーリングとドロップアウトの後に続く、それぞれ32、64、128の3X3フィルターで構成されます。
ぞれぞれの畳み込みモジュールのアウトプットはフィード・フォワード・レイヤーに投入されます。
完全に接続されたレイヤーは、低レベルから高レベルのフィルターのアウトプットへ順に接続し、最も効果的な機能を選択することができます。
フィード・フォワード・レイヤーは1,024個のニューロンからなる2層の隠れレイヤーで構成されており、追加のドロップアウト・レイヤーはそれぞれに接続されたレイヤーに適用されます。
ドロップアウトを頻繁に利用する理由は、オーバーフィッティングを避けることによって同じデータに関する様々なパターンをネットワークに学ばせるためです。
ドロップアウトを追加することの効果はこちらで説明しています。
最後のソフトマックス・レイヤーはモデル予測のlog-lossを計算するために使用されます。
更に、L2正規化コストが大型モデルの重みにペナルティーを科すために含まれています。
トレーニング
道路標識の大まかな特徴をモデルに学ばせるために大規模なオーグメンテーションから始め、モデルを最適化するために徐々にオーグメンテーションを縮小させます。
トレーニングは以下の手順で行います。
- データ・オーグメンテーションを使ってトレーニングセットの中のそれぞれの画像から10枚の新しい画像を作る。
- データをトレーニングセットと、トレーニングセットの25%に相当するバリデーションセットに分ける。
- 最初の10回のエポックの後、エポックあたり0.9のファクタをオーグメンテーションから減らしていく。
モデル・パフォーマンス
全てのパラメーターが識別されてから、モデルはNvidiaのTitan Xで約4時間のトレーニングを要しました。
トレーニングの後、テストのデータにおけるパフォーマンスは98.8%をわずかに超えました。
未知のアメリカの道路標識におけるモデル・パフォーマンス
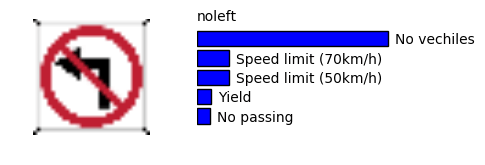
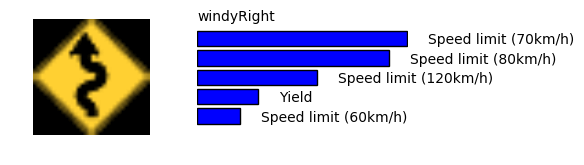
ドイツのデータセットに類似した標識の画像においてモデルは非常によく機能しました。
例えば、停止や進入禁止の標識は高確率で正確に認識されます。
成功例


失敗例
まとめ
このプロジェクトは非常に興味深く、ゼロから研究を始め文献で発表されている研究と比較できる程度まで取り組むことが出来ました。
また、更にモデルを改善できる点がいくつかあり、最も簡単に出来ることはモデルをより長時間トレーニングすることです。
各トレーニングのサイクルは約4時間掛ったため、最適な学習率や正規化を選択するためのハイパー・パラメーター・オプティマイゼーションを行いませんでした。
原文
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。