機能
機能概要
メイン機能
- ユーザ機能
- オペレータ(対人チャット)機能
- 管理者機能
サブ機能
- SNS連携
- アバター連携
- シナリオ機能
- 多言語対応機能
- API機能・仕様
機能詳細 / 操作マニュアル
サポートサービス
基本的には、チャットボットは以下の手順で導入/運用を進めていきます。各工程にてサポート致しますので、ご不明点等ございましたらお気軽にご相談下さい。
正しいチャットボットの導入・運用 研修も行っております、詳細はこちら。
導入ガイド
簡易 導入ガイド
一問一答のFAQ形式の導入ステップ
- FAQデータ(CSV)の用意
- FAQデータのインポート
シナリオ形式の導入ステップ
シナリオ式とは、ユーザとチャットボットが対話形式で、シナリオを展開・対応していく方法です。
- シナリオ・データ(CSV)の用意
- シナリオ・データのインポート
詳細 導入ガイド
正しいチャットボットの導入・運用 研修(詳細はこちら)
現状分析
要件定義
Q&A作成・登録
CSV等のFAQデータを元に、データをユーザー用管理画面から投入します。
チャットボットに聞かれると想定されるQ&Aをなるべく多く洗い出し、Q&Aとして登録する作業を行います。
実際の投入方法は操作マニュアル:Q&Aの章を参照して下さい。
以下、Q&A、シノニム、固有名詞を考える際の注意点です。
- 同じ回答をチャットボットが行うと思われる質問で、以下の例のように質問の文章の表層が大きく異なる場合は、すべて1つの質問の盛Qとして登録して下さい。(「SPJの住所は?」=「SPJはどこにあるの?」等)
- 質問の形式は敬語ではない形で登録して下さい。(☓「SPJはどこにありますか?」、○「SPJはどこにあるの?」)
- 同じような質問・回答はなるべく1つにまとめて下さい。「SPJはどこにあるの?」と「SPJは何区にあるの?」は回答としては細かく分けると別になる事が考えられますが、住所を回答することで2つの質問は1つの回答にまとめられます。
- 通常ユーザーから来る質問文はそれほど長くないため、なるべく~30文字程度で質問文を作成して下さい。
- 後々「チャットボットを賢くしていく方法」によってチャットボットの精度は改善していくため、ある程度思いつく限り入れたらまずは投入して、精度向上サイクルを回していくことを推奨します。
- 同義語を登録することで対応できる盛Qは、盛Qとしては登録せずに同義語の方を優先して登録するようにして下さい。例えば「SPJの住所は?」と「SPJの所在地は?」という2つの質問を入れるのではなく、「SPJの住所は?」だけを質問として登録し、シノニムとして「住所」=「所在地」を登録して下さい。
- アルファベットの大文字・小文字は考慮されませんのでご注意下さい。(iPhoneとiphoneは同じ単語として扱われます)
- 質問文に存在する、固有名詞は固有名詞のメニューから登録して下さい。例えば「スーパートマト」という商品名があった場合、固有名詞として登録することによって単に「トマト」という文字が質問として出てきてもスコアは高くならず、「スーパートマト」という文字が出てくるとスコアが高くなります。登録していない場合は、「スーパートマトを買った」という文章と「スーパーでトマトを買った」という文章は同じ文章(スコア)として扱われます。
- すべてのQ&Aの投入後、管理画面からコミットを行って下さい
- 同義語が存在する単語を含めたQを作成する場合、1種類の同義語のみを使用するようにして下さい。例えば「スマホ」=「iPhone」の場合、「スマホ」のみを使用した文章を作成し、同義語として「スマホ」=「iPhone」を登録して下さい。(同義語が「スマホ」=「Android」等複数になった時に2つ目の同義語以降がヒットしなくなるため)
対話シナリオ作成・登録
FAQ自動生成(詳細はこちら)
テスト
Webサイトへの設置
カスタマイズ開発
御社オリジナルのUI、機能 開発、他システムとの連携 等のご要望が御座いましたら、カスタマイズ開発も可能ですので、お気軽にご相談下さい。
運用ガイド
- 精度向上支援
- ログ分析支援
- ログレポート作成
- 効果測定
- 各種お問合せメールサポート
チャットボットを賢くしていく方法
チャットボットは質問やシノニムを追加していく事でより精度の高い回答をすることが可能です。各フェーズでの注意点を記載します。
また、実際の運用後は、ログ分析や、学習モードのアウトプットを確認し、QAのナレッジを向上させる事で、回答のカバー率を上げることもできます。
運用モードを使う方法
評価モードにてブラインドテスト(どんなQ&Aを登録されているかを知らされていない被験者が、自由に質問を投げていくテスト)を行う事でチャットボットの学習を行います。
下記の手順で学習を行います。被験者の人数は多いほど精度が早く精度が向上していきます。
- デモシステム画面にログインし、「運用モード」または右下のウィジェットを開きます。
- 自由に質問文を入力し、正解の質問候補を選択します。無ければ「該当なし」を選択します。
- 2の作業を数十回から数百回程度繰り返します。管理画面上のウィジェットログにログが溜まっていることを確認してください。
- 管理画面の「ウィジェットログ」を選択します。
- CSVダウンロードし、Excelにて開き、ヒット順位が-1であるデータをフィルタリングして表示します。これらのデータがユーザーの質問に対する回答がなかったデータとなります。(学習オプションが有効な場合は、この操作は不要です。学習メニューのページを開いてください)
- ユーザーが入力した質問が、すでに既存のQ&Aにある質問の別の言い方である場合はシノニムの追加もしくは盛Qの追加を行います。
- デモシステム画面の聞き返しモードを開き、追加した質問を入力し、正しい回答が一番上に来るかどうか確認します。
- 6,7の作業を最後のデータまで繰り返します。
- 次に、ヒット順位が1でも-1でもないデータを表示します。(これらのデータは、質問にはヒットしているが、一番目にはヒットしていないデータです。質問候補としては出ているのでユーザーはその質問を選択することにより回答にはたどり着くことが可能ですが、これらのデータから新たなシノニム・固有名詞のヒントを得ることが出来ます。また、この質問データは学習モードの場合は自動で表示されます)
- 表示されたデータから、同義語・固有表現を追加する事でより順位が上がりそうな場合、追加します。
- コミットを行います。
- 過去に正しくヒットしたデータについても再度チャットボットに投げて、正しく回答が返ってくるかどうかをチェックします。(プログラムが書ける場合はAPIを使用すると素早くチェックが可能です。)
運用後のQAナレッジの向上による方法
ログ分析を使用する方法
ログ分析のアウトプットには、独自のAIアルゴリズムにより、ユーザからのクエリで質問の意図があるものが、重要度の高い順に表示されます。
この中で、重要度が高く、またよく繰り返されているクエリの中で、既存のQAに該当の質問が登録されていない場合、それらのクエリは、QAのナレッジを向上させていくのに重要なクエリとみなすことができます。これらのクエリを参照して、新たにQAを生成し、チャットボットに追加していく事で、チャットボットの回答のカバレッジを上げていく事が可能になります。
学習モードを使用する方法
操作マニュアル:学習 を参照
ログ分析レポートと精度改善 事例
基本的には、ご提供する管理画面のログと、利用マニュアルをご覧頂ければユーザー企業様にて、ログ分析と精度改善を行って頂く事は可能です。
但し、もしご希望のお客様には、弊社にてログ分析と精度改善サービスをご提供致しますので、お気軽にご相談下さい(オプション・サービスとなります)。
以下、フラワーショップ向けAI店員 分析レポート例
(AI店員、AIチャットボットと同一のAIエンジンで構成しています。)
花屋に設置したAI店員チャットボットとユーザーがXXXX年XX月にユーザーとの会話を行ったログを収集し、分析した結果を下記に示す。
1. カテゴリ別会話数
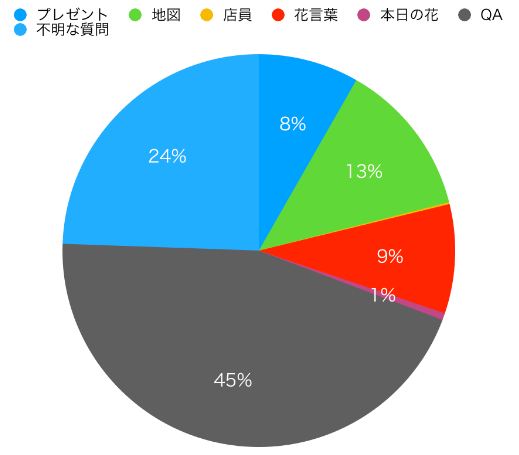
2. 地図表示Q&Aに対する分析
想定していた質問は「大宮駅への行き方を教えてください」、「大宮駅にはどうやって行ったらいいの?」のような質問であった。
ただ、質問内容を機械学習でクラスタリングを行い、想定される質問に該当しないグループを抽出した所、23%のユーザーが下記のような質問で場所を聞いていた。
「◯◯◯を売っている場所は?」
「◯◯◯が食べられるとこを教えて」
(この◯◯◯に入るのは場所名でなく、商品名・食べ物名等となる。)
元々は場所名が質問内容に入っている想定で、質問内容から場所を固有表現抽出を行っていたが、商品名・食べ物の名前を抽出してそれぞれ売っている店鋪・飲食店を提案するように変更したことにより、場所について聞かれた際のチャットボットの回答の精度を18%向上に成功した。
3. 不明な質問に対する分析
不明な質問とは、チャットボットが判断できない(どの想定QAにも一定のスコア以上類似していない)ユーザーからの質問のことである。
機械学習によるクラスタリングの結果、大まかに下記のように質問が分類された。
各クラスタに対する改善策も同時に示している。
| クラスタ | 例 | 割合 | 改善策 |
|---|---|---|---|
| 花の説明 | ・ポインセチアの説明して ・薔薇ってどこの? ・薔薇の産地は? | 12% | 花の解説QAを導入する |
| 名詞のみ | ・福岡県 ・結婚式 ・薔薇 | 11% | ・[場所の場合]=>地図表示スクリプトへ遷移 ・[花名の場合=>花の注文スクリプトへ遷移 |
| 想定外の依頼 | ・音量を下げて ・踊って | 8% | 「分かりません」ではなく、「出来ません」のような返答にする |
| ・日本語以外、意図不明な文章 ・音声認識に失敗している、その他 | ・関する ・眠い ・電車が来ない ・ありましたハローズ | 69% | ※音声認識失敗の改善案を参照 |
音声認識失敗の改善案
音声認識に失敗しているせいでうまくマッチしていない文章がいくつかある。
「関する(元:キャンセル)」「木の実の(好みの)」
これらは元々話そうとしている文章とは表層としては全く類似していないため、不明な文章として取られてしまっていた。
この問題の改善策として、元々ユーザーから想定されている質問文章のローマ字読みをインデックスし、ユーザーからきた発言のローマ字読みとのLevenshtein distanceを測り、マッチングさせた。
kansuru = kyanseru
konomino = konomino
この結果、音声認識に失敗している例の中の45%の文章で正しくマッチングさせることができた。
残り55%に関しては、そもそも想定されていない文章だと考えられるため、Q&Aの追加により向上すると思われる。
4. 精度改善結果
上記の改善点を盛り込み、再度1週間ログを取得しそれまでの回答精度と比較を行った結果が下記となる。
| カテゴリ | 精度改善前 | 精度改善後 |
|---|---|---|
| 花注文 | 36.7% | 33.3% |
| プレゼント | 5.6% | 3.2% |
| 地図 | 7.2% | 12.0% |
| 店員 | 2.8% | 2.3% |
| 花言葉 | 5.3% | 3.6% |
| 本日の花 | 3.1% | 0.2% |
| QA | 21.1% | 24.9% |
| 不明な質問 | 32.0% | 20.5% |
全体として11.5%の精度改善が行われ、79.5%の質問に対して正しく回答することが出来るようになった。
5. 今後の改善案
チャットボットが現状日本語にしか対応していないが、ユーザーからの意味不明な文章がログで散見され、これの音声を実際に聞いてみると、英語や中国語の質問であった。
そのため、不明な質問と判断された文章の元の音声ファイルを全件言語認識にかけ、実際の言語を判定すると下記結果となった。
- 英語 76%
- 中国語 9%
- スペイン語 2%
- 不明・その他 13%
上記の結果から、英語に対応させ、英語の質問に対して7割の精度で回答ができるようになったとすると全体としては8.8%の精度向上につながると考えられる。
また、不明な文章と判断された際に回答として「すみません、分かりませんでした」と発言しているが、この回答をした際の次のユーザーの発言に対し感情分析を行った所、58%の割合で不満を示していた。
そのため、ここの発言を「分かりませんでした」ではなく店員を呼ぶような挙動や、「申し訳ございません、勉強中でその質問は回答できません」のようなユーザーの気分を害しないような発言に変更することが望ましいと考えられる。