概要
数週間にわたって、私はリアルタイムで車両検出を行うことができるアルゴリズムの開発に力を注いでいます。
アルゴリズムの開発にあたって、arXivから深層学習に関する論文をいくつか読みました。
何かを学ぶための最良の方法は自らが実際に操作を行うことだというのが私の信条です。
そうすれば、論文を読んだときや他者が作ったコードを見たときに見逃してしまうような細かい内容も理解することができます。
ですので、根本的なアイデアと可能性の限界点を見極めるために、実際に物体検出における深層学習のアーキテクチャーをいくつか作りました。
今後数週間の内に、このアーキテクチャーの中からいくつかを精査するつもりです。
この記事では、シングルショット マルチボックス検出モデルを運用して得られた結果について検証してみましょう。
学習
アルゴリズムの多くは他の物と異なり比較的小さな一連のアイデアが基になっていることに気がつきました。
それらをセグメンテーションベースモデルとスケールベースモデルという二つの種類に分類しました。
セグメンテーションベースモデルでは、ピクセルがオブジェクトであるかどうかを決定するために画素単位予測(ピクセルワイズプレディクション)というものを作成します。
Unetディープラーニングアーキテクチャーはこのようなセグメンテーションモデルの一例です。
もう一方のスケールベースモデルは、強力な分類器を構築し、大きさ(解像度)を変えた画像からいくつか部分的に切り取った画像の断片をその分類器に通し、画像の断片がオブジェクトであるかどうかという可能性を調べることが主な考え方です。
異なる解像度でこの過程を繰り返すことによって、多様なサイズやアスペクト比の物体も検出することができます。
これは多くのイメージピラミッドをベースにしたコンピュータビジョンアプリケーションの根本的な考え方と同じです。
このアイデアはディープラーニングニューラルネットワークでも用いられています。
例えばSPPNetでは、五番目のコンボルーショナルブロック(VGGNetのconv5)の次にあるスペーシャルプールレイヤーから送られたフィーチャーマップは様々な画素数のコンボルーショナルレイヤーを通された後、平滑化レイヤーに集められ識別器へと送られます。
異なる画素数のフィーチャーを組み合わせることで、SPPNetは異なる画素数での物体の識別が可能になります。
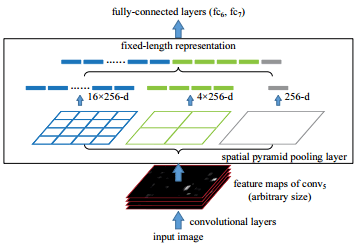
リージョンプロポーザルとプーリングを組み合わせるフレームワークは、いわゆるリージョンベースの畳み込みニューラルネットワーク (R-CNN)に属しています。
そこにはR-CNN、fast-RCNN、faster-RCNNという三つの発展型があります。
R-CNNでは物体がある位置の可能性を特定するためにセレクティブサーチアルゴリズムを使用し、そして事前訓練されたコンボルーショナルニューラルネットワークを通して様々な区画の画像を送ります。
R-CNNでは画像の様々な部分をコンボルーショナルボックスに通すため、計算時間とオーバーヘッドが高くなります(1フレームあたり50秒)。
この膨大な計算時間を軽減するためにfast-RCNNは開発されました。
コンボルーショナルネットワークにはインプットする画像のサイズに制約はありません。
したがって効率的な計算方法は、まず解像度の高い画像をコンボルーショナルブロックに通し、コンボルーションを行なったフィーチャーマップでセレクティブサーチを実行することです。
得られたフィーチャーマップはROIレイヤーを通って7X7(平滑化レイヤーによって予測された)のサイズに変更され、画像の予測に使用されます。
この方法では1つの画像に要する時間を2秒に短縮することができます。
皮肉なことに、フィーチャーマップに用いられたリージョンプロポーザルアルゴリズムは大きな計算を要する過程でした。
この問題を軽減するために、faster-RCNNではそれぞれのピクセルの位置に9個のアンカーボックスのセットを配置するリージョンプロポーザルネットワークが提案されました。
このアンカーボックスのセットはオブジェクトがそのピクセルの位置および該当する境界ボックスに存在するかどうかを判断する予測を行います。
非最大抑制テクニックを用い、これらの境界ボックスが選択された小数の物体候補に結合されます。
そして、その物体候補はROIプールレイヤーを使用してサイズ変更され、コンボルーショナルニューラルネットワークのフィードフォーワードへと送られます。
このテクニックなら予測時間は1秒あたり5~7フレームへ大幅に短縮されます。
しかし、5~7フレームというのは計算上の時間であり、リージョンプロポーザルネットワークから各画像をROIプールレイヤーと予測レイヤーに通す過程は多くの計算を要します。
YOLO(英:You Look Only Once)は同じネットワークを用いて境界ボックスとクラスラベルの予測を行いこれらの問題のいくつかを解決しようとします。
YOLOでは最終レイヤーの各ピクセルに対して境界ボックスとクラスの予測を行います。
また境界ボックスを検出するために非最大抑制が用いられます。
一方、YOLOではこの予測は7対7の形の最後のマックスプーリングブロックで行われ、この変換は7対7のグリッドに分割されたオリジナルの画像に基づいて予測を行います。
その結果、YOLOは背景の変化によってエラーが発生しやすくなります。
YOLOの動作は非常に速いのですが(1秒あたり約45フレーム;小型は約150フレーム)、faster-RCNNよりも精度と検出率は低くなります。
シングルショット マルチボックス検出器
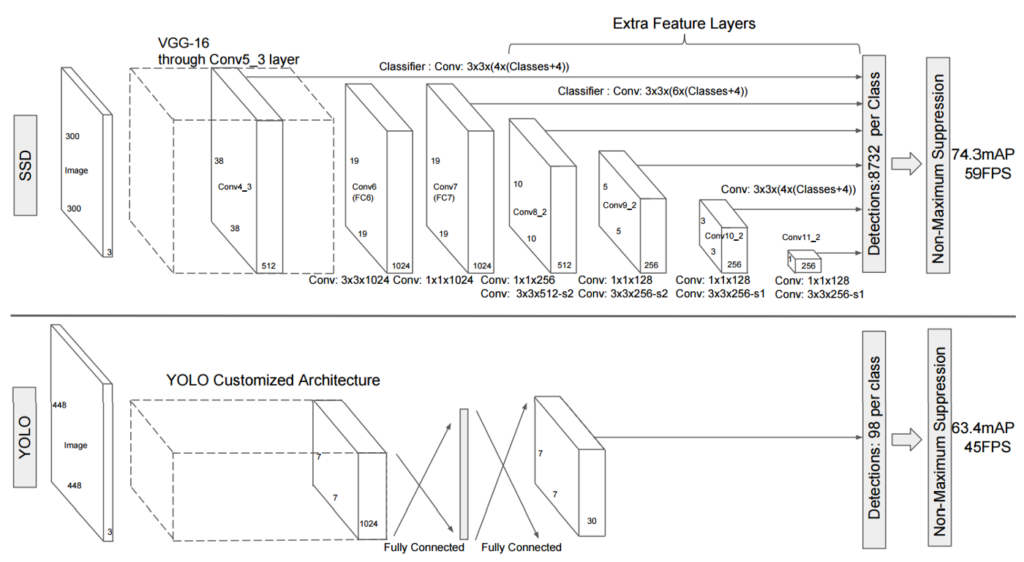
最終的なアーキテクチャー及び本ポストのタイトルはシングルショットマルチボックス検出器(SSD)と言います。
SSDはコンボルーショナルネットワークの異なる段階で作られたフィーチャーマップを基に予測をすることによって、YOLOの低い解像度の問題に対処します。
それによってSSDは最先端のfaster-RCNNと同じ、もしくは場合によってより正確になります。
これは元の画像に近いレイヤーの方が高い解像度を維持できるためです。
境界ボックスの数を管理し続けやすくするために、Atrousコンボルーショナルレイヤーが提案されました。
Atrousコンボルーショナルレイヤーは高速でデータ処理を行うためにサブサンプルに空のフィルターを用いるウェーブレット信号処理の「algorithme a trous」に着想を得ています。
下の図では収集された様々なコンボルーショナルブロックのフィーチャーからマルチスケール(またはマルチボックス)検出器が構成されることを示しています。
各フィーチャーマップにおいてクラスラベル及び境界ボックスを予測します。
この方法の利点は、フィーチャーが様々なスケールのフィーチャーマップから集められるので、全体的なアルゴリズムは異なるスケール及びサイズの物体の検出ができ、さらにfaster-RCNNよりも精度が高くなります。
その上、予測がたった一回のデータ送信で行われるので、SSDはfaster-RCNNと比べ格段に速くなります。
VOC2007のデータセットでは、SSDは59FPSでmAPが74.3%、faster-RCNNは7FPSでmAPが73.2%、mAPに7fps、YOLOは45fpsでmAPは63.4%というパフォーマンス結果になりました。
実験
論文の結果に基づきSSDモデルがUdacityのデータセットから入手した静止画における車両検出タスクでどのように機能するかをテストしました。
素早くプロトタイピングするため、VOCデータセットで学習させた既存のモデルを使用し、最後のフィードフォワードレイヤーを私たちのフィードフォワードレイヤーと交換しました。
この作業によって、以前の全コンボルーショナルレイヤーと新しいフィードフォワードレイヤーとの接続を再設定することが必要となりました。
最初の4つコンボルーショナルブロックのウェイトで作業を中断し、モデルをUdacityのデータで再学習させました。
結果
下の図はUdacityの代表的なデータを表示していますおり、以下のように各車は境界ボックスによってラベル付けされています。

下の図ではモデルは自動車のみを検出するように修正され予測を表示しています。

予想した通り、学習前のネットワークを用いたら上手く機能しませんでした。
次に32エポックの学習後にどのように機能するか見てみます。
Adam gradient optimizerの0.0001の学習率を使用しました。車両及び境界ボックス予測は以下の図で表示されています。
ボックス内には物体が自動車であるというモデルの判断の確かさを数値化して表示しています。

以上のように、SSDモデルは高い精度で車両を検出することができます。
SSDネットワークの予測時間は約20ms、つまり50fpsということになります。他のコードと組み合わせたらその時間は増加しました。
境界ボックス予測の時間は20ms、画像を読み込み前処理する時間は約40ms、境界ボックスを描く時間は250~270msであり、1フレームあたりの合計の処理時間は280〜330msで、Titan X computerでのスピードは3〜5fpsとなりました。
明らかにこのコードはマルチスレッドによる最適化をされていませんでした。良い解決法は予測パイプラインをサーバーとして動作させ、別の描画プログラムを使用することでしょう。
今後数週間かけて私たちはニューラルネットワークと描画の作業を並行して行い、うまくいけば32fpsの検出率に達することができるようにプログラムを改良するつもりです。
感想
このプロジェクトは非常に複雑なアーキテクチャーモデルを応用した大変興味深いものでした。
研究資料で報告されたデータの45fpsには届かず、私が達成できたのは僅かの3〜5fpsでした。
ですが、低いfps率は私が読み込み、画像の前処理、予測、画像に作図する工程を順次行った結果です。
作図作業は最も時間がかかるので、良い解決法は予測サーバーを作図コマンドと並行して作動させることです。
連続で作画作業を作動させた場合、性能が10分の1になってしまうことに驚きました。
今後数週間の間で、より高いfps率を出せるように予測作業と作画作業を別々に作動させることができるようにするつもりです。
更新
本ポストを書いてから、MATLABの代わりにCV2のプロットルーチンを使用し始め40〜50fpsの検出率を果たすことができました。
原文
https://chatbotslife.com/towards-a-real-time-vehicle-detection-ssd-multibox-approach-2519af2751c
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。