あらすじ
この記事では、オンライン教育サイト:Udacityによって提供された動画における車両検知のためのU-Net使用方法について記載していきます。
U-netはピクセル単位の予測の為のエンコーダー・デコーダータイプのネットワークです。
トレーニング後に、ネットワークは都市環境において車両を正確に認識できるようになり、さらに興味深いことに正しく注釈のつけられた車に対しては、そのパフォーマンスは人間よりも優れていました。
以下では、私たちが都市環境においてU-netが車両を検出できるようするため、どのようなトレーニングを行ったのか、データ処理の手順、拡張手法そしてトレーニングの詳細について説明していきます。
この方法は、U-netに関するオリジナルの研究論文とKaggleのultrasound segmentation challengeの入賞作品にインスパイアされたものです。
データ
私たちはUdacityから提供された注釈のついた車両データセットを使用しました。
4.5GBのデータセットは米国のマウンテンビュー周辺をUdacity車両が走行中に撮影した2つの動画から収集されたフレームで構成されています。
データセットには乗用車、トラックそして歩行者を示す バウンディングボックス・ラベルファイル(図形を囲う四角い枠)が含まれていました。
全体のデータセットは約22,000の画像で構成されています。
私たちは乗用車とトラックを一つのクラスの車両として統合し、全ての歩行者のバウンディング・ボックスは考慮しませんでした。
主な理由としては、データセット内の乗用車の数がトラックと歩行者の数をはるかに上回っていたからです。
データの準備とオーギュメンテーション
はじめにデータをトレーニングデータセットとテストデータセットに分割しました。
フレームはビデオフィードから得たもので、それぞれのフレームは一つ前のフレームに依存していたため、私たちは残りの2,000画像をテスト用とし、残った画像をトレーニング用としました。
その後データセットのオーギュメンテーションを行いました。
また、今回のプロジェクトでは3回のみオーギュメンテーションを行いました。
それらは、ストレッチ、トランスレーション、ブライトネス(明るさ)のオーギュメンテーションです。
ボックスの長方形を維持するために私たちは特にこの3つのオーギュメンテーションを選択しました。
私たちが検討していたもう一つの興味深いオーギュメンテーションは、垂直軸に対して画像をランダムに回転させるというものでしたが、今回は使用しないことにしました。
興味のある方は、左側の運転席(アメリカのような)の画像を反転させることで、インドや他の右側の運転席の国のトラフィックパターンにデータに変更することができます。
ストレッチ
下の図はどのようにストレッチのオーギュメンテーションを行ったかを示しています。
初めに、オリジナルの画像の四隅近くにポイントしました(紫色)。
その後、それらのポイントが新しい境界となるように拡大、新しいボックスに応じて修正を行いました。
ボックスの外の画像を捨てなかったのは、画像をはっきりとさせるためです。
スケーリング・オーギュメンテーション前と後


トランスレーション
次に様々な場所で移動する車両の効果をモデル化するためにトランスレーション変換を適用します。
トランスレーション前と後


ターゲットセットの準備
典型的なピクセル単位の予測では、初めに対象となるものの周りにマスクとなるポリゴンを描画しました。
今回の場合、私たちはその情報を持っていなかったため、対象を定義するためのマスクのようなボックスを使用しました。
その後、それらのマスクを使って、それらと同じサイズのマスクを作成し、以下の図にも示されています。
左の画像は、もともとの画像に オーギュメンテーション を施すことによって得た画像で、中心の画像は予測を行う車両マスクを示し、最後の画像は、実際にマスクが車両を認識するということを確認するため、マスクを元の画像に適用した結果を示しています。
私たちのニューラル・ネットワーク・モデルの目標は、与えられた左の画像から、中心の画像のようなマスクを検知することです。
オーギュメンテーション画像、マスク、そして適用されたマスクはスケーリング、トランスレーション、ブライトネスから生成しています。




モデル
私たちが選んだモデルは、U-netと呼ばれるディープラーニング・アーキテクチャの縮小バージョンです。
U-netは画像分割のためのエンコーダー・デコーダータイプのネットワーク・アーキテクチャです。
アーキテクチャの名前はそのユニークな形状からきており、U-netは、ガンや腎臓病そして細胞トレースなどを検出する医療用途向けに広く用いられています。
U-netは限られたデータ(時には50以下のサンプルデータ)におけるシナリオで非常に効果を発揮するセグメンテーションツールであることが証明されています。
U-netを使用するもう一つの利点としては、それが完全に結合されたレイヤーを持たないことで、それゆえ入力画像のサイズ制限がないことです。
この機能によって、様々なサイズの画像から特徴を抽出することが可能になります。
この特徴は、忠実度の高い医療用画像データにディープラーニングを適用するための魅力的な機能です。
ごくわずかなデータで作業ができ、入力イメージのサイズに関して特定がないというU-netの能力は、画像セグメンテーションにおいて非常に強力な候補となります。
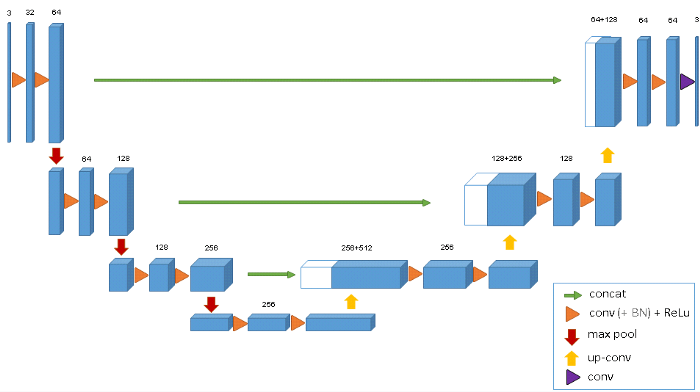
U-netへの入力は、リサイズされた960 X 640の3チャンネルRGBイメージで、出力は960 X 640の1チャンネルの予測マスクです。
私たちはその予測に車両かどうかのピクセルの見込みを反映させたかったので、最後のレイヤーにシグモイド関数を使用しました。
トレーニング
どの畳み込みニューラルネットワークでも、トレーニングには多くの時間がかかりました。
Full U-netのTitan X GPUに1以上のサイズのバッチを収めることができなかったため、全てのアーキテクチャにサイズ1のバッチを選ぶことを決めました。
この1つの画像はランダムにサンプリングされ、全てのトレーニング画像から オーギュメンテーション されたものです。
バッチサイズ1を選択したため、学習率0.0001のAdamオプティマイザを選択しました。
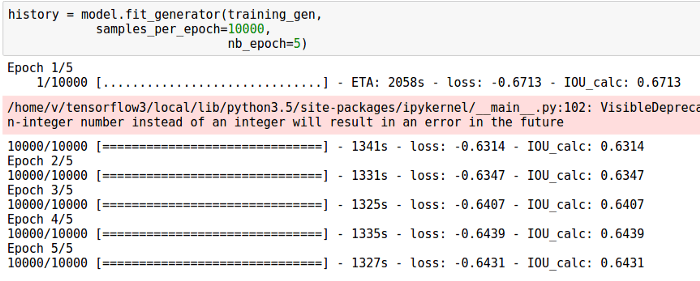
トレーニング自体をセットアップすることは複雑ではありませんでしたが、10,000回の反復を行うのに私のGPU:titan Xは約20分を要しました。
目的
ネットワーク出力とターゲットマスク間の近似交差(IoU)を計算するために、kerasで目的関数を定義しました。
IoUはバウンディングボックスを含むタスクのための一般的なメトリックです。
IoUは常に1と0の間で変化し、IoUを最大化することが目的であり、私たちはIoUの負の値を最小化することを選択しました。
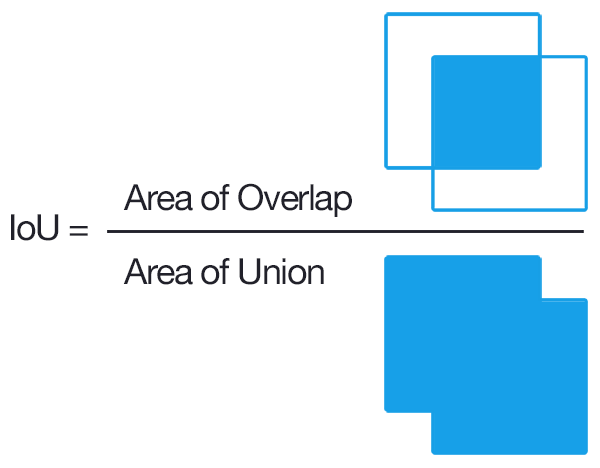
ユニオンやクロスエントロピーによる交差を直接計算する代わりに、ターゲットマスクのネットワーク出力を2乗し、実際のマスクを出力された予測値の合計で割るという、よりシンプルなメトリックを使用しました。
このトリックは複雑な計算を避けることに役立ち、結果としてトレーニング時間を短縮することができました。
結果
私たちは2時間後にトレーニングを停止し、ネットワークを予測に用いることにしました。
テスト時間において、オーギュメンテーションは予測に適用されませんでした。
アルゴリズムは驚くほど早く、ディスクからのファイルの読み取りと描画を含む、10の予測を行うのに200msしかかかりませんでした(画像あたり平均20ms)。
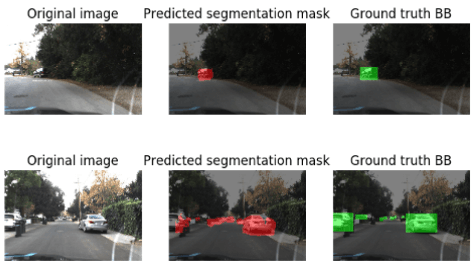
以下の図は、車両検出モデルの現時点のパフォーマンスを表しています。
それは驚くべきもので、ニューラルネットワークは以前にはできなかった運転中のフレームから、正しく車両を識別することができました。
以下の図は車両予測に適用されたセグメンテーション・アルゴリズムの現時点での結果です。
パネルはオリジナル画像、予測されたマスクそしてグランドトゥルーボックスを表しています。

人間のパフォーマンスよりも優れています
以下は、IoU値が低かったいくつかの例です。
しかし、さらに調査したところ、それらのケースはデータセットにおいて車両がマークされていませんでしたが、セグメンテーションモデルは車両に正しく位置していることがわかりました。
これは、私たちのモデルが車両検出を学び、単純にトレーニングデータのレプリカを作るだけではないということを強く示唆しています。

異なった場所を車両として検出した間違った例もいくつかありましたが、そのような例はテストデータセットではほとんどありませんでした。

最後にモデルが初見のデータに対してどのくらい正しい結果を導き出すのかをテストするため、高速道路を走行中の画像でU-netアルゴリズムを実行しました。
以下の図はモデルが、走行中のレーンとその反対のレーン両方の車両を正しく検出したことを示しています。
より驚くべきことは、ガードレールによって遮られた車両を検出したことです。
私はU-netが検出した赤いマークを見るまでは、それが車両であると気づきませんでした。
このアルゴリズムはいくつかの領域を車両であると検出したのです。
これは、どの車両も見逃さないという事実であり、私たちはこのアルゴリズムが成功した検出アルゴリズムであると考えています。

まとめ
これは多くの理由から非常に興味深いプロジェクトでした。
比較的自然なデータセットでセグメンテーションモデルを実行するのは今回が初めてで、私のTitanX GPUが苦戦しているのを見たのも今回が初めてです。
全体的に、結果には非常に満足しており、U-netアーキテクチャがこれほどうまく車両検出を学習したことに驚いています。
いくつかのケースにおいては、人間がマーキングしたオリジナルのデータセットよりパフォーマンスが優れていました。
ガードレールの向こう側の赤いマークを見るまで私が見逃していた反対のレーンの車両を正しく検出した時には特に驚きました。
そのケースでは、ネットワークは私よりも正しく動作しており、また、私はそれを誇らしく思いました。
注意すべき重要な点はモデルが正しく実行され、データセット内においてマークされていなかった車両も検出したことです。
これはエラーのより少ないデータセットを選ぶことによって、モデルのパフォーマンスをさらに高めることができるということを示唆しています。
もしモデルのパフォーマンスが向上したら、次はKITTIやそのほかのソースやテストからのデータを組みこもうと思っています。
次の目標
- 他のコスト関数、特に真のIoUと交差エントロピー損失関数を試す
- 複数のデータのマージと新しいデータにおけるモデルのパフォーマンス・チェック
- 事前にトレーニングされたデータのU-netモデルの畳み込み部分への使用と、オブジェクト検出の高速化のためのROIプーリングとセグメンテーションの統合
参考情報
- 様々なセグメンテーションモデル:https://handong1587.github.io/deep_learning/2015/10/09/segmentation.html
- Kaggleの受賞作品: https://github.com/jocicmarko/ultrasound-nerve-segmentation
原文
https://chatbotslife.com/small-u-net-for-vehicle-detection-9eec216f9fd6
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。