※サンプル・コード、Githubへのリンクも掲載
1. あらすじ
チャットボットブームに際し、過去数ヶ月間、NLP(自然言語処理)、及びDeep learningをどのようにチャットボットに適用するか、関連リソースを集めていました。
常に有用なコンテンツをリストに収集するようにして、可能な限り細かく収集を行ったつもりです。
今回、そのリストをチャットボットの開発者、及びその他の方にシェアします。
このリストは、チャットボット分野におけるDeep learningの経験豊富なDenny Britzによって、ソースコードと、Githubへのリンクが提供されており、ユーザにとって、チャットボットの作り方のガイドとなります。
チャットボット選定で“絶対に外せない”3つの確認ポイントとは?

本資料(無料 eBook)をご覧頂ければ、以下の事がスムーズに出来る様になります。
- 選定候補のAIチャットボットを客観的に比較する事
- 実機トライアルで準備・確認すべき事
- 自社に最適なサービスを見つけ、失敗せずに導入する事
2. チャットボットのためのDeep learning 概要
チャットボットは現在大変流行していて、多くの会社が、NLPやDeep learningを使用して、チャットボットで自然な対話を実現させる事にチャレンジしています。
しかしながら、これを実現するのは現在のAI技術では容易ではありません。
本章では、対話システム分野で使用されているDeep learning技術について、何が可能で、何が不可能かについて解説していきます。

3. 対話モデルの分類:検索ベースと、生成ベースのモデルについて
検索ベースのモデルは、入力(インプット)・コンテキスト・経験に基づき、決まったレスポンスを返します。
それは、ルールベースマッチのようにシンプルなものでも、機械学習のアンサンブル的手法のような、難しい手法でも達成できます。
このモードの場合は、回答を生成する事は無く、決まったリソースの中から、回答を文字通り検索します。
生成ベースのモデルの場合、決まったレスポンスを返すのではなく、ゼロから新しいレスポンスを生成します。
生成ベースのモデルは、機械翻訳関連の技術を使用しており、ある言語を別の言語に翻訳する代わりに、入力(インプット)を出力(アウトプット)へ翻訳します。
これがレスポンスになります。
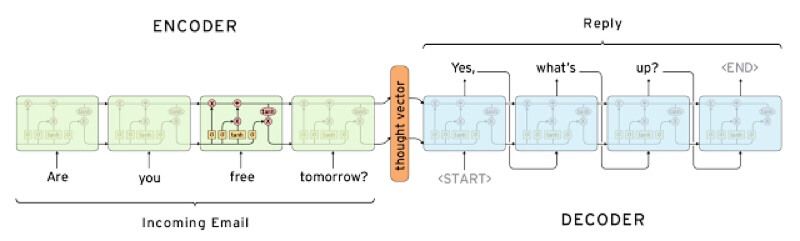
どちらのアプローチにも長所と短所があります。
決まったリソースから回答を用意するため、検索ベースモードでは文法のエラーは起こりえません。
しかしながら、検索ベースモードでは、想定外のインプットに対して対処する事ができない弱さがあります。
また、同じように、会話の継続性を意識した際に、過去の会話で、人の名前等、コンテキストとして重要な発言があったとしても、それらを過去の会話の中から参照する事ができません。
一方、生成ベースモデルは、検索ベースモデルに比べると、「賢い」モデルであるといえます。
生成ベースモデルは過去の会話の中の重要な情報を参照しながら、人間のような会話を実現する事ができます。
しかし、このモデルはトレーニングする事が非常に難解で、文法のミス等が多発する可能性があります。
そして、通常、モデルのトレーニングには大量のデータを要します。
Deep learningはどちらのモデルにも適用可能です。
どうやら最先端の研究領域では生成ベースモデルとの関わりが強いようです。
機械翻訳等で用いられている、Deep learningの一技術の、「 sequence to sequence 」等は、会話を自動生成させるのに向いており、この分野の突破口として期待されています。
しかし、生成ベースモデルはまだ時期尚早なので、商用には検索ベースモデルを用いるべきでしょう。
チャットボット選定で“絶対に外せない”3つの確認ポイントとは?
本資料(無料 eBook)をご覧頂ければ、以下の事がスムーズに出来る様になります。
- 選定候補のAIチャットボットを客観的に比較する事
- 実機トライアルで準備・確認すべき事
- 自社に最適なサービスを見つけ、失敗せずに導入する事
4. 長い会話 vs 短い会話
会話が長くなればなる程、それを自動化する事は難易度の高い作業となります。
当然、回答が予測できる短い会話の方が、それを自動化する事は容易なのですが、カスタマーサポート等で使用される会話は、複雑な質問が入り組んだ長い会話となる事が多いです。
5. オープンドメイン vs クローズドドメイン
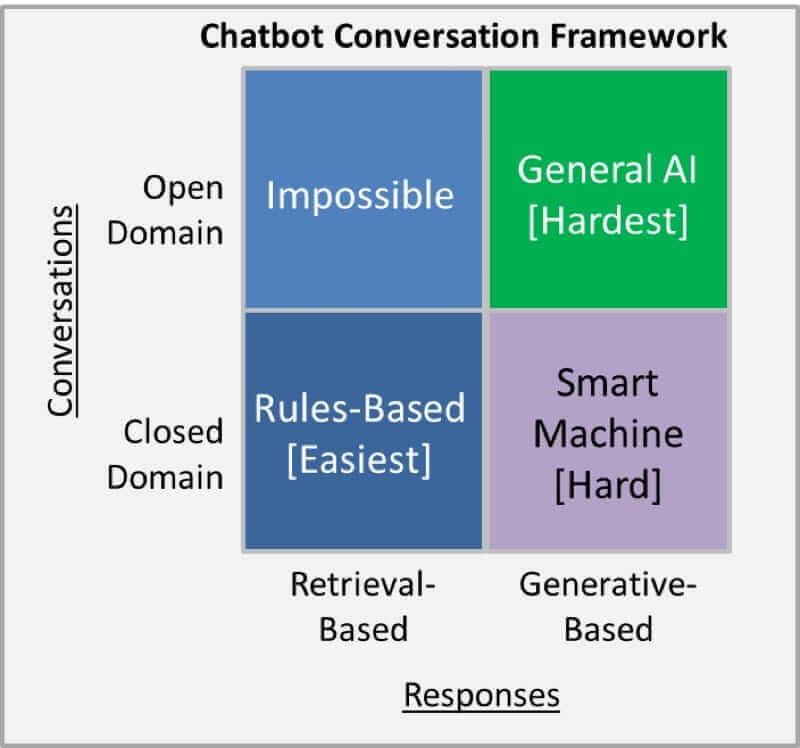
オープンドメインは雑談等、ユーザの会話のトピックの内容が予測不可能な会話のドメインを指しており、Twitter等のSNSの会話などは、オープンドメインとなる事が多いです。
この場合、トピックの範囲は多岐に及ぶため、まともな会話を実現する場合、前提知識が数多く必要となります。
クローズドドメインは、あるシステムで想定される使い方を対象とするため、入力はある特定の分野に絞られ、出力も限られています。
技術的なカスタマーサポートや、ショッピング中のアシスタント等が、クローズドドメインの典型的な例です。
この場合、会話システムは、宗教等、関係ない話題に対応する必要も無く、またユーザもそれを望んでいないのです。
完全な目的特化型会話システムと言えるでしょう。
6. 会話システムを実装する際の難しさ
会話システムを実装する際に、明白な課題とそうでない課題とが、最先端の研究領域でよく議論されています。
6-1. コンテキストの理解
会話システムに説得力のあるレスポンスをさせる場合には、会話のコンテキストの理解が重要になります。
これを実現するのに最も一般的なアプローチは、会話をベクトル表現に変換することですが、それは長い会話の場合当然負荷が高くなります。
最先端の研究においてはこれらのアプローチに関心が向いており、会話情報だけでなく、日付や時間、位置情報などの付随情報もコンテキストとして取り扱う必要があります。
6-2. AIの人格
AIが人格を意識して質問に回答できるようになることはとても大切です。
例えば「何歳ですか?」というような簡単な質問を投げかけられた際でも、いつどんな状況で誰と会話しているかで、回答の言い回しは変化するでしょう。
人間はこういった操作を簡単に行っていますが、AIにこのような対応をさせようとすることは最先端の研究領域での話であり、非常に難易度が高くなります。
ほとんどのシステムは、先程の質問に対して、「39歳です」のような一般的な回答を返すでしょう。
それは色々なソースを使用して一般的なトレーニングを行っているため、AIがそのように学習しているのですが、個々の人格を意識した、AIのパーソナル化の側面を意識する事は大事で、そういった研究も盛んになってきています。

6-3. 会話モデルの精度測定の難しさ
会話システムの精度を評価する際に理想的な精度評価方法は、システムが目的のタスクを達成したかどうかでモデルの精度を評価する事ですが、これは判定が非常に難しいタスクです。
特にオープンドメインでは、会話中の回答で、何が正解なのかを定義することが難しい場合も多いので、機械翻訳等で使用されている、BLEU等の一般的な精度評価のメトリックを適用できない場合が多いです。
ダイアログシステムを評価できない事に関して:教師無しの学習で用いられている、ダイアログの生成を評価するメトリックはどれも、人間の判断と合致するものが無いという実証的な検証結果があります。
6-4. 回答における多様性を実現する難しさ
生成ベースモデルの難しさは、多くの場合何を質問しても「それはいいね」「それは知らない」など、非常に一般的な回答を返してしまうようになってしまうことです。
まさに初期のGoogle smart replyに顕著にその傾向が見られました。
これはシステムの構成や、モデルがどうトレーニングされたかに基づいています。
研究者達は日々この状況を打破し、より多様性のある回答を生成するため日々精進しています。
7. 実際にどのように効果的に機能するのか?
最先端技術を全て加味した上で、AIは今どのくらいの事ができて、どのくらいの事ができないのでしょうか?
もう一度、2つのモデルについておさらいしてみましょう。
検索ベースモデルでは、当然全てのオープンドメインを取り扱う事は難しいです。
生成ベースモデルでオープンドメインに挑むのは、もはやAGI(汎用AI)に立ち向かうようなものです。
つまり、AIはまだまだ未熟と言わざるを得ません。
さて、そういった背景があるので、AIがフォーカスすべき領域は、検索ベース、及び生成ベースのモデルがどちらもフィットする、限られたドメインに絞られることになります。
ここでも、会話が長く複雑になればなるほど、それを取り扱うことが難しくなります。
多くの会社が、十分なデータが集まりさえすれば、人間の会話を自動化できるといってビジネスを開始していますが、これは、Uberのチャット上でタクシーを手配する等、極めて狭いドメインに絞られた会話でのみ成立する話です。
少しでもドメインが広がってしまうと途端に機能しなくなってしまいますが、それでもこういったAIシステムは、人を手助けするために使用できるし、それはむしろ望まれる使い方です。
商用のシステムでは文法のエラーなどは致命傷になる可能性があり、多くのユーザを遠ざけてしまう可能性があります。
それが多くの会社が検索ベースモデルを使用する理由ですが、その分野で十分なデータが集まると、生成ベースモデルも有用になります。
しかしながら、MicrosoftのTayが差別的な発言をして、世間を賑わせてしまったように、間違いを犯してはならないので、そういった発言をしないようなチェックは重要になります。
8. Tensorflowで検索ベースモデルを実装してみよう
8-1. 検索ベースのボット
現在のほとんどのチャットボットは検索ベースであると言えるでしょう。
(一部は、生成ベースモデルと組み合わせているようですが。)
GoogleのSmart replyが良い例で、生成ベースモデルは非常に研究が盛んな領域ですが、我々の技術はまだそこに追いついていません。
今、商用のチャットボットを実装するならば、検索ベースモデルを使用することを推奨します。
8-2. UBUNTUダイアログコーパス(UDC)
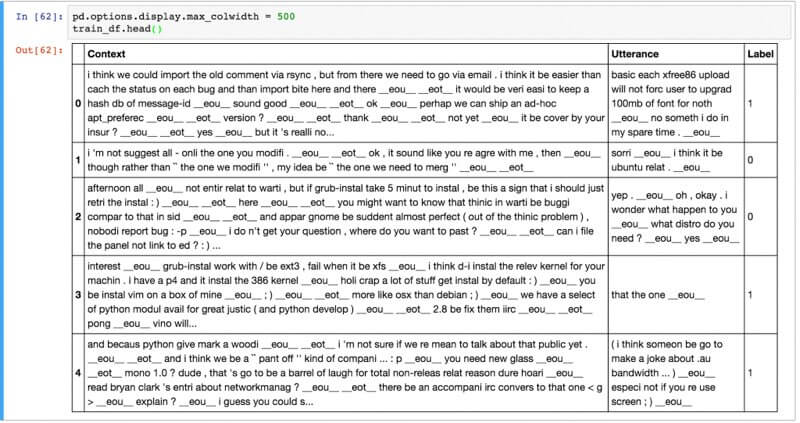
このポストでは、以下のUBUNTUダイアログコーパス,(paper,github)を使用します。
UDCは対話ダイアログコーパスで有名なものの1つで、チャットのログから構成されます。
UDCは100万の例文から構成され、50%ポジティブ、50%ネガティブなタグがデータに施してあります。
ポジティブなタグはそれまでの一連の会話のコンテキストに対して正しい反応をした時、ネガティブなタグはその逆となります。
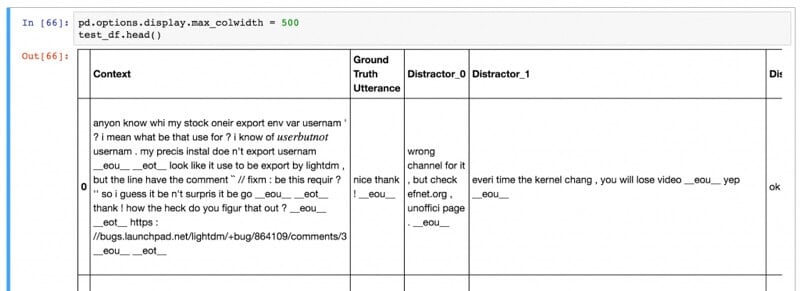
以下にデータのサンプルを掲載します。
NLTK toolを使用し、形態素解析やステミング、分類等、NLPの前処理をデータに対して施しました。
また、人名や地名、組織名等のエンティティに関しても同様に前処理を施しました。
これらの処理は厳密には必要とされていないですが、この処理を施すことで少し精度を上げることができます。
コンテキストは平均86字程度で、発話は平均で17字程度です。
Jupyter notebookをチェックして、データ分析を確認してください。
データセットは、テストセットと検証用のセットから構成され、これらのフォーマットはトレーニングデータのものと異なります。
テストセットと検証用のデータセットは、コンテキスト、実際の発話での反応、及び、9つの不正解の発話の反応で構成されています。
モデルのゴールは、正解の発話に一番高いスコアを生成し、不正解のものに低いスコアを生成する事です。
モデルには様々な評価方法があり、一番有名なメトリックの測定方法は、Recall@k と呼ばれます。
これは、モデルに合計10個のレスポンス(1つのみ正解で、9つは不正解)の中からK個のレスポンスを選ばせ、この中に正解がある場合は、正解とマークをします。
つまりこの場合、Kの値が大きくなると、タスクの難易度は比例して下がっていきます。
(k=10の場合は、どんな場合でも確実に正解となる)
この時点では、9つの不正解がどのようにして選ばれるのか不思議に思うかもしれませんが、これらデータセットから、全くランダムに選ばれます。
ただ、実世界では、想定できないくらいのレスポンスがあり、決して定量化できません。
8-3. 基本
ニューラルネットのモデルを始める前に、パフォーマンスを見るために非常にシンプルなモデルから取り組みましょう。
recall@k メトリックを使用するために、以下の関数を用います
def evaluate_recall(y, y_test, k=1):
num_examples = float(len(y))
num_correct = 0
for predictions, label in zip(y, y_test):
if label in predictions[:k]:
num_correct += 1
return num_correct/num_examples
yはここでは、降順にスコアでソートされた予測の結果で、y_が実際の正解ラベルを表しています。
例えば、yが [0,3,1,2,5,6,4,7,8,9] である時、0が最も高いスコアを獲得したことになり、9が最も低いスコアとなっています。
つまり、リストの中の最初の値はいつも正解となります。
recall@1の時に、完全にランダムな予測器は10%の精度となり、recall@2の時は、20%の精度となりました。
以下が、ランダムな予測器のコードとなります。
# Random Predictor
def predict_random(context, utterances):
return np.random.choice(len(utterances), 10, replace=False)
# Evaluate Random predictor
y_random = [predict_random(test_df.Context[x], test_df.iloc[x,1:].values) for x in range(len(test_df))]
y_test = np.zeros(len(y_random))
for n in [1, 2, 5, 10]:
print(“Recall @ ({}, 10): {:g}”.format(n, evaluate_recall(y_random, y_test, n)))
Recall @ (1, 10): 0.0937632
Recall @ (2, 10): 0.194503
Recall @ (5, 10): 0.49297
Recall @ (10, 10): 1
さて、ランダムな予測器だけではパワフルではないので、より精度を上げる仕組みを考えてみましょう。
ここでTFIDF(term frequency — inverse document)という仕組みを導入します。
TFIDFは単語の頻度と、その単語がドキュメントのセットの中でどのくらい重要かを評価する指標で、単語の重要度の重み付けを行う仕組みです。
これを利用すると、同じような内容のドキュメントのTFIDFの単語ベクトル表現は似たベクトルに近づいていくことになります。
TFIDFを使用する事により、ランダム予測器よりも高い精度の予測器を実装可能になる可能性があります。
class TFIDFPredictor:
def __init__(self):
self.vectorizer = TfidfVectorizer()
def train(self, data):
self.vectorizer.fit(np.append(data.Context.values,data.Utterance.values))
def predict(self, context, utterances):
# Convert context and utterances into tfidf vector
vector_context = self.vectorizer.transform([context])
vector_doc = self.vectorizer.transform(utterances)
# The dot product measures the similarity of the resulting vectors
result = np.dot(vector_doc, vector_context.T).todense()
result = np.asarray(result).flatten()
# Sort by top results and return the indices in descending order
return np.argsort(result, axis=0)[::-1]
# Evaluate TFIDF predictor
pred = TFIDFPredictor()
pred.train(train_df)
y = [pred.predict(test_df.Context[x], test_df.iloc[x,1:].values) for x in range(len(test_df))]
for n in [1, 2, 5, 10]:
print(“Recall @ ({}, 10): {:g}”.format(n, evaluate_recall(y, y_test, n)))
Recall @ (1, 10): 0.495032
Recall @ (2, 10): 0.596882
Recall @ (5, 10): 0.766121
Recall @ (10, 10): 1TFIDFモデルは、ランダムモデルよりも遥かにいい精度になりました。
ただし、まだ完璧には程遠いです。
これには、コンテキストを考慮したレスポンスが必ずしもTFIDFベクトルとして近いものになっていない、また、TFIDFで文章の語順を考慮できない、という2つの原因があります。
さて、そこでニューラルネットのモデルを使用して、これらの課題に取り組んでみます。
8-4. デュアルエンコーダーLSTM
Deep learningベースのモデルは、デュアルエンコーダーLSTMをネットワークとして使用します。
このモデルは、本課題に対して適用できるケースの1つで、決してベストなモデルというわけではありません。
Deep learningに関する研究は今まさに盛り上がっているため、様々なネットワークが提案されており、それらの全てを試す事は容易では無いです。
この場合、機械翻訳でよく用いられているseq2seq技術がフィットするでしょう。
デュアルエンコーダーはを使用する理由は、本データセットにおいて、非常に良いパフォーマンスが見られたためです。
これが意味するのは、私達のアプローチが正しい方向に向かっているであろうということと、今後、様々なDeep learningのテクニックを適用し更に大きな飛躍が見込めそうだということです。
Deep learningベースのモデルの挙動を大まかに説明すると以下のようになります。
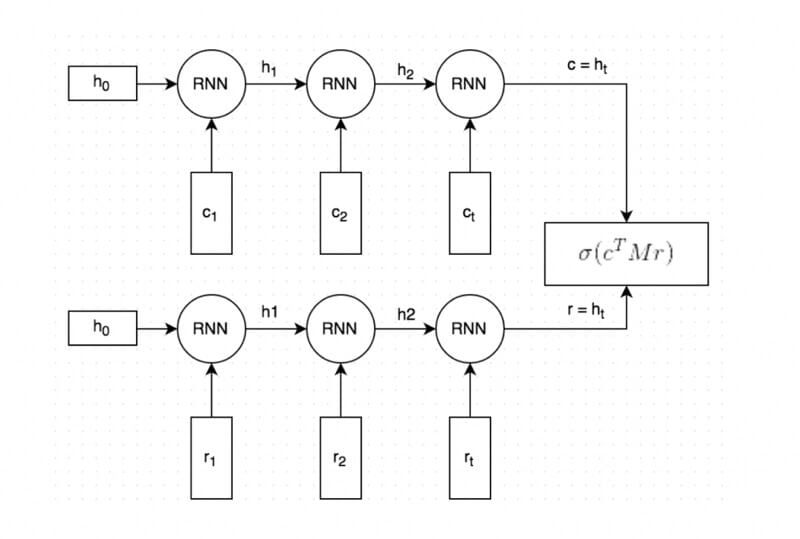
1.コンテキストと回答のテキストはどちらも単語で表現され、単語はGloveを用いてトレーニングされたモデルを使用して、分散表現で表されます。
2.分散表現のコンテキストとレスポンスは、単語毎に同じRNNに渡されます。RNNはコンテキストとレスポンスを加味したベクトル表現(図中のcとrに対応)を生成します。ベクトルのサイズは調整可能ですが、今回は256次元に固定します。
3.cを行列Mと掛け合わせて、レスポンスrを計算します。cが256次元のベクトルの場合、行列Mは256*256次元の行列である必要があります。そして計算されて得られるrは256次元のベクトルとなります。このrこそが、モデルによって生成されたレスポンスに相当します。行列Mはトレーニング時に学習されます。
4.予想されたレスポンスr’と、生成されたレスポンスrの間のベクトルの距離を計算する事で、スコアを計算します。より近いベクトル表現ほど、当然スコアも高くなります。そして得られたスコアをシグモイド関数を用いて確率値に変更します。(本ステップ3と4は図の中では合わせて描かれています。)
ネットワークをトレーニングするために、損失(コスト)関数が必要となります。
ここでは、バイナリクロスエントロピーという損失関数を用います。
また、コンテキストのレスポンスを表しているyペアを正解ラベルと命名します。
ラベルに関しては、1の時に実際のレスポンスを表し、0の時に間違ったレスポンスを表します。
そして、先程のステップ4のy’から、予測された確率を呼び出しましょう。
この際に、クロスエントロピーによる損失は以下のように計算されます。
L= −y * ln(y’) − (1 − y) * ln(1−y’).
式の意味としてはy=1の時は予測確率値は1から遠ざかり、y=0の時はその逆となります。
8-5. データの前処理
オリジナルのデータセットはCSVフォーマットですが、Tensorflow固有のフォーマットに変更する事をおすすめします。
これによるメリットは、Tensorをファイルから直接呼び出せるようになり、Tensorflowにシャッフルや、バッチ処理、待ち行列処理などを任せられる点です。
データ前処理の一部で、ボキャブラリーについても構築を行います。
ボキャブラリーとは、全ての単語をキーにして対応するユニークな整数を値とする辞書を生成することです。
また、逆に整数をキーとして、単語を値とする辞書も生成しておきます。
全ての例では以下のフィールドを含みます。
- context: コンテキストのテキストを表す一連の単語ID(例 [231, 2190, 737, 0, 912])
- context_len: コンテキストの長さ(上記の例では5)
- utterance: レスポンスを定義する一連の単語ID
- utterance_len: utteranceの長さ
- label: トレーニングデータにのみ存在し、0か1を取る
- distractor_[N]: テストデータ、または検証用データにのみ存在し、0から8の間の値を取りうる。不正解のutteranceの単語IDを表す
- distractor_[N]_len: distractor_[N]の長さを表す
前処理はprepare_data.py Pythonスクリプトによって実行されます。
このスクリプトは、train.tfrecords、validation.tfrecords、およびtest.tfrecordsという3つのファイルを生成します。
スクリプトを自分で実行するか、ここでデータファイルをダウンロードすることができます。
train.tfrecords
validation.tfrecords
test.tfrecords
8-6. 入力関数の作成
Tensorflowに組み込まれた、トレーニングと検証のためのサポートを使用するために、入力関数の作成が必要になります。
入力関数は、入力データをまとめて返す関数であり、トレーニングデータと、テストデータでは異なったフォーマットとなっており、それぞれ別々の入力関数が必要となります。
その場合入力関数は、特徴量と(存在する場合)ラベルをまとめて返す必要があります。
def input_fn():
# TODO Load and preprocess data here
return batched_features, labelsトレーニングと検証で別々の入力関数が必要となり、それを分けて作成することは手間なので、create_input_fnと呼ばれるラッパーの関数を作成し、その関数から適切なモードを呼び出します。
def create_input_fn(mode, input_files, batch_size, num_epochs=None):
def input_fn():
# TODO Load and preprocess data here
return batched_features, labels
return input_fn完全なソースコードはudc_inputs.pyです。この関数は以下の役割を果たします
- Exampleファイルのフィールドの特徴量の定義を作成
- TFRecordReaderを用いて、input_filesからレコードを読み込む
- 特徴量の定義によってレコードをパースする
- トレーニング用のラベルを抽出
- 幾つかの例とトレーニングのラベルをまとめる
- まとめられた例と、トレーニングのラベルを返す
モデルを評価する際に、recall@k メトリックを使用することにはすでに触れましたが、幸運な事にTensorflowはデフォルトで、recall@kを含んだ幾つかの有用なメトリックを提供してくれます。
これらを使用するためには、予測結果とラベルを引数とした関数に、メトリックの名前を関連付ける辞書が必要になります。
def create_evaluation_metrics():
eval_metrics = {}
for k in [1, 2, 5, 10]:
eval_metrics[“recall_at_%d” % k] = functools.partial(
tf.contrib.metrics.streaming_sparse_recall_at_k,
k=k)
return eval_metrics上記ではfunctools.partialを使用して、3つの引数を、2つの引数に変換する関数を作成しています。
これには評価時の予測のフォーマットが正確にはどうなっているのかという疑問があります。
トレーニング時は、サンプルの正解確率は正しいと予測しましたが、検証時は、正解と9つの不正解のスコアを測定し、ベストなスコアのものを選びます。
つまりこれが意味するのは、検証時は正解、不正解をシンプルに決定できるわけではなく、以下のように10個のスコアで表されるベクトルを取り扱います。
[0.34, 0.11, 0.22, 0.45, 0.01, 0.02, 0.03, 0.08, 0.33, 0.11]常に正しいレスポンスは配列の0番目なので、各確率を足し合わせて1にする必要はありません。
上記の配列の例では、recall@1 では、3番目の成分の確率値が、0番目より高いために不正解となり、recall@2 では正解となります。
8-7. トレーニングコードのたたき台
ニューラルネットを使用したコードを実装する前に、トレーニングとモデルを評価するためのたたき台のコードを実装します。
たたき台のコードがあれば、内部のネットワークは何を使用していても交換可能なため、利便性を考えてそうします。
estimator = tf.contrib.learn.Estimator(
model_fn=model_fn,
model_dir=MODEL_DIR,
config=tf.contrib.learn.RunConfig())
input_fn_train = udc_inputs.create_input_fn(
mode=tf.contrib.learn.ModeKeys.TRAIN,
input_files=[TRAIN_FILE],
batch_size=hparams.batch_size)
input_fn_eval = udc_inputs.create_input_fn(
mode=tf.contrib.learn.ModeKeys.EVAL,
input_files=[VALIDATION_FILE],
batch_size=hparams.eval_batch_size,
num_epochs=1)
eval_metrics = udc_metrics.create_evaluation_metrics()
# We need to subclass theis manually for now. The next TF version will
# have support ValidationMonitors with metrics built-in.
# It’s already on the master branch.
class EvaluationMonitor(tf.contrib.learn.monitors.EveryN):
def every_n_step_end(self, step, outputs):
self._estimator.evaluate(
input_fn=input_fn_eval,
metrics=eval_metrics,
steps=None)
eval_monitor = EvaluationMonitor(every_n_steps=FLAGS.eval_every)
estimator.fit(input_fn=input_fn_train, steps=None, monitors=[eval_monitor])
トレーニングと検証データ、及び、検証用のメトリック辞書を入力として取る、2つの入力関数を実装し、model_fnを推定します。
また、トレーニング時の全てのステップで、FLAGS.eval_モデルを評価するモニターを実装します。
そして最終的にモデルのトレーニングを開始しますが、Tensorflowはチェックポイント毎に、MODEL_DIRに関連ファイルをセーブするため、いつでもトレーニングを中断する事が可能です。
もしくは、アーリーストップという手法で、モデルのトレーニングを早期終了させる事も可能です。
コードの全貌はこちらで確認可能です。
FLAGSの使い方について説明しておきます。
これはPythonのargumentを受け取る時のようにhparamsはモデルにパラメータを渡す時に使用されます。
これは、モデルを初期化した時に呼び出されます。
8-8. モデルの生成
入力、パース、検証とトレーニングに関してたたき台のコードを用意したので、デュアルLSTMによるニューラルネットのコードの実装に進みましょう。
create_model_fnは、トレーニング時と検証時のモデルのフォーマットの差を吸収する役割があります。
これを使用する事により、他のネットワークへの移行も簡単に行なえます。
def dual_encoder_model(
hparams,
mode,
context,
context_len,
utterance,
utterance_len,
targets):
# Initialize embedidngs randomly or with pre-trained vectors if available
embeddings_W = get_embeddings(hparams)
# Embed the context and the utterance
context_embedded = tf.nn.embedding_lookup(
embeddings_W, context, name=”embed_context”)
utterance_embedded = tf.nn.embedding_lookup(
embeddings_W, utterance, name=”embed_utterance”)
# Build the RNN
with tf.variable_scope(“rnn”) as vs:
# We use an LSTM Cell
cell = tf.nn.rnn_cell.LSTMCell(
hparams.rnn_dim,
forget_bias=2.0,
use_peepholes=True,
state_is_tuple=True)
# Run the utterance and context through the RNN
rnn_outputs, rnn_states = tf.nn.dynamic_rnn(
cell,
tf.concat(0, [context_embedded, utterance_embedded]),
sequence_length=tf.concat(0, [context_len, utterance_len]),
dtype=tf.float32)
encoding_context, encoding_utterance = tf.split(0, 2, rnn_states.h)
with tf.variable_scope(“prediction”) as vs:
M = tf.get_variable(“M”,
shape=[hparams.rnn_dim, hparams.rnn_dim],
initializer=tf.truncated_normal_initializer())
# “Predict” a response: c * M
generated_response = tf.matmul(encoding_context, M)
generated_response = tf.expand_dims(generated_response, 2)
encoding_utterance = tf.expand_dims(encoding_utterance, 2)
# Dot product between generated response and actual response
# (c * M) * r
logits = tf.batch_matmul(generated_response, encoding_utterance, True)
logits = tf.squeeze(logits, [2])
# Apply sigmoid to convert logits to probabilities
probs = tf.sigmoid(logits)
# Calculate the binary cross-entropy loss
losses = tf.nn.sigmoid_cross_entropy_with_logits(logits, tf.to_float(targets))
# Mean loss across the batch of examples
mean_loss = tf.reduce_mean(losses, name=”mean_loss”)
return probs, mean_loss完全なソースコードはdual_encoder.pyで確認できます。
以前定義したudc_train.pyのメイン関数で、モデルを初期化できます。
model_fn = udc_model.create_model_fn(
hparams=hparams,
model_impl=dual_encoder_model)これで、udc_train.py を走らせれば、トレーニングを開始できます。
トレーニングを開始すると、以下のように、定期的に検証用データセットに対してRecallを測定します。
INFO:tensorflow:training step 20200, loss = 0.36895 (0.330 sec/batch).
INFO:tensorflow:Step 20201: mean_loss:0 = 0.385877
INFO:tensorflow:training step 20300, loss = 0.25251 (0.338 sec/batch).
INFO:tensorflow:Step 20301: mean_loss:0 = 0.405653
INFO:tensorflow:Results after 270 steps (0.248 sec/batch): recall_at_1 = 0.507581018519, recall_at_2 = 0.689699074074, recall_at_5 = 0.913020833333, recall_at_10 = 1.0, loss = 0.5383モデルのトレーニング終了後、以下のコマンドでモデルの検証ができます。
python udc_test.py — model_dir=$MODEL_DIR_FROM_TRAINING検証用のセットでなく、テストセットでrecall@kの検証を走らせる際には、以下のコマンドを実行します。
python udc_test.py — model_dir=~/github/chatbot-retrieval/runs/1467389151Udc_test.py を呼ぶ際は、トレーニング時と同じパラメータを用いる必要があります。
recall_at_1 = 0.507581018519
recall_at_2 = 0.689699074074
recall_at_5 = 0.913020833333recall@1はTFIDFモデルに近いですが、recall@2とrecall@5は非常に精度が上がりました。
ニューラルネットのモデルが、正しい回答により高いスコアを与えている事が示唆されました。
ただし、この検証結果は、元々参照した論文の精度よりは低く、それに並ぶためには、データの前処理をもっと工夫したり、ネットワークのパラメータの調整が必要になるかと思います。
8-9. 予測してみよう
未知のデータに対して、確率スコアを得るためにudc_predict.pyを編集する事ができます。
以下のコマンドを実行してみましょう。
python udc_predict.py — model_dir=./runs/1467576365/
Context: Example context
Response 1: 0.44806
Response 2: 0.481638コンテキストに対して取りうる100個のレスポンスを投げて、一番スコアが高い結果を返した場合の検証結果です。
9. まとめ
この記事では、会話のコンテキストを意識したレスポンスに対して、スコアを付与する検索ベースのニューラルネットモデルを実装しました。
これにはまだまだ改良の余地があります。
また、今回のデュアルLSTMエンコーダー以外のニューラルネットのネットワーク構造のパフォーマンスが上回る可能性もあるので、まだまだチューニングの余地があるかと思います。
原文
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。
参考資料
https://github.com/dennybritz/chatbot-retrieval/
Denny Britz: http://blog.dennybritz.com/ & http://www.wildml.com/
Mark Clark: https://www.linkedin.com/in/markwclark
あとがき
この記事が皆様のお役に立てば大変光栄です。
本当はこの5倍の長さの記事をポストする予定でしたが、皆様を嫌にさせたくなかったので、この長さにまとめました。
もし、あなたがチャットボットのUI/UX部分の開発者であれば、NLPではカバーできない多くの問題に対して、違ったアプローチで解決をすることができるようになると思うので、非常に有益でしょう。
チャットボット選定で“絶対に外せない”3つの確認ポイントとは?
本資料(無料 eBook)をご覧頂ければ、以下の事がスムーズに出来る様になります。
- 選定候補のAIチャットボットを客観的に比較する事
- 実機トライアルで準備・確認すべき事
- 自社に最適なサービスを見つけ、失敗せずに導入する事