あらすじ
チャットボットの新しいグラフィカル・ユーザー・インターフェース(GUI)が増えるにしたがって、それらを構築するためのフレームワークも増加しています。
チャットボットの新しいトレンドは、例えば、FobiのようなWebサイトでたった1回のクリックによってGoogle Forms形式からチャットボットへと変換できるサービスを提供するという成果をもたらしました。
また、DialogFlowやWitなどのボットフレームワークでは、ほとんどコードを使うことなく相当に単純な作業で、僅か数分の間に洗練されたチャットボットを作り、稼動させることができるようになりました。
チャットボット選定で“絶対に外せない”3つの確認ポイントとは?

本資料(無料 eBook)をご覧頂ければ、以下の事がスムーズに出来る様になります。
- 選定候補のAIチャットボットを客観的に比較する事
- 実機トライアルで準備・確認すべき事
- 自社に最適なサービスを見つけ、失敗せずに導入する事
チャットボットの3つの要素
チャットボットの構築には主に以下の3つの要素が含まれています。
- 自然言語理解(NLU:Natural Language Understanding)
- 対話
- コントローラー
自然言語理解の唯一の役割はユーザーのインプットから意味を抽出することです。
特に:
- ユーザーがボットに対して言いたいことの中核となる「意図」
- それが持つ重要な情報(エンティティ)

例えば上記の例だと、ユーザーが発した「暖房の設定」が意図で、「21°C(華氏70度)」、「寝室」が動作を実行させるために必要とされる意図の実体(エンティティ)です。
実体とは意図次第であり、例えば、あなたが求める情報が場所と料理の種類なら、ユーザーの意図(ユーザーインテント)はレストランの検索であって、リマインダーの追加ではありません。
意図を指定する方法はいくつかあり、例えば、ユーザーが天候の詳細を求めている場合の下記の意図を参考に考えてみましょう。
- 「今日の天気はどうなりますか?」
- 「今日の天気予報を教えてください」
- 「今日傘を持って行く方がいいの?」
- 「さっさと外の様子を教えろ!」
これらの文は、ボットにとっては同じ意味になることをユーザーは異なる表現で表しています。
それではボットはどうやってこれら人間の言語の複雑さに対応するのでしょう?
簡単に言うと、あなたのドメイン内のあらゆる意図と実体の例をボットに与え教えこむのです。
そうすることで、ボットはマシンラーニング・アルゴリズムを使用して自動的にパターンを学習し、だんだんとあなたと同じように意図と実体を識別することができるようになります。
マシンラーニングの専門用語で表すなら、意図の特定は文章分類、エンティティの認識は固有表現抽出を通して行われます。
両タスクについては個別で記事を書くべきだと思いますが、あなたがボットフレームワークを使用するならそれらについての知識は必要なく、それこそがボットフレームワークの素晴らしい点です。

自然な会話にする為に
実際の会話には多様な表現が用いられ、会話は数分から数時間と続きます。
人間は会話の中で文脈を推察し、その文脈に従って会話を進めることができます。
以下はダイアログ・コンポーネントを設定するところで、チャットボットのフローを作るためにこのようなGUIを使うことができます。
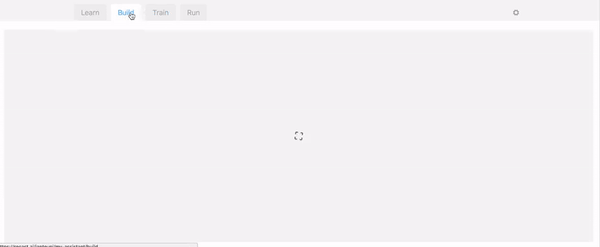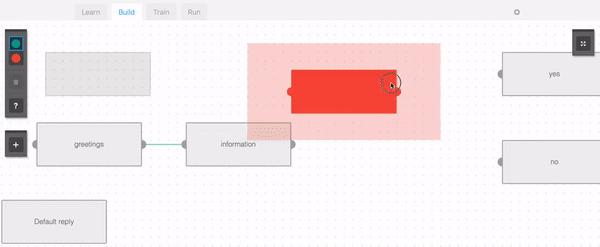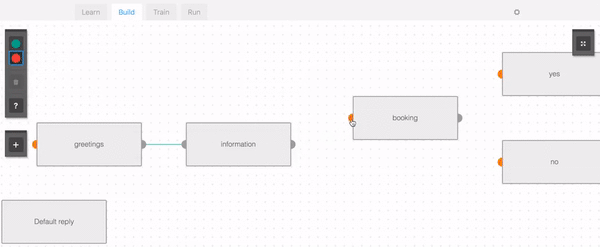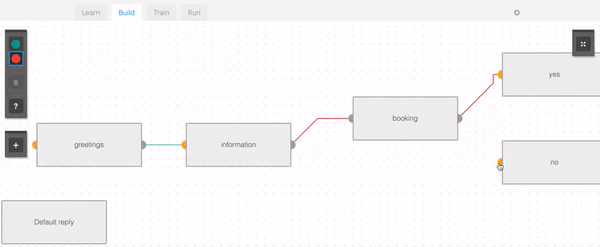
またはこのようなファイルで書き表すこともできます。
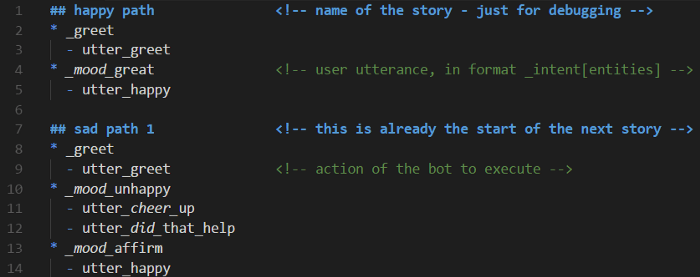
または、強化学習(RL:Reinforcement Learning)を用いて書かせることもできます。
全てのシナリオを書く代わりに、ボットは進行中の会話を基に動作を選び、あなたがそれに対してフィードバックを与えます。
そしてボットはそのインプットから学習し、自らグラフを作成します。
このボットのトレーニングプロセスをオンライン・マシン・ラーニングと呼びます。
これはフローを構築する労力を省いているわけではなく、ただ単にやり方を変えているというだけのことです。
時間かけてボットにその動作に関するフィードバックを与える必要があることに変わりはありません。
また、ダイアログ・コンポーネントはNLU(自然言語理解)コンポーネントから抽出された情報とあなたが作ったルールに基づいて、どのようなアクションをとるかを決めます。
チャットボットとユーザーとのやり取りを通し、あなたが作成したグラフを基にしたいくつかの選択肢の中から一つしか選択することしかできません。
いつでも抽出されたエンティティを会話の文脈として保存し、あなたが作ったルールに沿ってそれを発展させたり消したりすることができます。
ユーザーが映画館の空席状況を調べるといった場合のような、より複雑な動作に挑戦したい場合はバックエンドサーバーを作り、抽出された情報をそこへ送ります。
そうするとサーバーは要求されたAPIコールを行い、その結果を会話のコンポーネントへと送り、そして会話のコンポーネントは得られた結果を用いて会話を続けます。
このシステムのために構築されたバックエンドサーバーはWebhookと呼ばれます。
そのボットは、ユーザーが伝えたいことを認識し、重要な情報を抽出して会話中それらの情報を記憶します。
そして、彼や彼女の好きなレストランの席を予約するといった動作を行うことができます。
そしてあなたが次に必要なものは、ユーザーが会話をするあなたのヒューマノイドを乗せるWebアドレスでしょう。
おすすめの方法は、Slack、Facebook Messenger、Telegramなどのボットプラットホームに接続することです。
大抵のフレームワークでは一つのクリックでこれができますが、自分でこの作業をしたいのならBotkitを使用することで自分のコントローラーを作ることもできます。
チャットボット選定で“絶対に外せない”3つの確認ポイントとは?
本資料(無料 eBook)をご覧頂ければ、以下の事がスムーズに出来る様になります。
- 選定候補のAIチャットボットを客観的に比較する事
- 実機トライアルで準備・確認すべき事
- 自社に最適なサービスを見つけ、失敗せずに導入する事
機械学習の活用
マシンラーニングは素晴らしい方法ですが、チャットボットを作る唯一の方法ではありませんし、そのテクニックはマシンラーニングの使用量によっても大きく左右されます。
例えば、AIMLは16年前に導入されたチャットボットをコード化するためのプログラミング言語なのですが、そこにマシンラーニングは全く必要とされておらず、全てのパターンを自分で書く必要があります。
そのためチャットボットの成長とともに非常に複雑化していきます。
この記事で紹介したテクニックでは、ユーザーの発言から意図とエンティティを特定するためにマシンラーニングを用いることで、いくつかのパターンマッチングを省略しましたが、依然としてチャットボットのフローを明確にする必要がありました。
もしあなたがその工程を省きたいなら、それをニューラルネットワーク(NN)に任せることができます。
数千の会話の実例を与えるだけで、ニューラルネットワークは自ら会話することを学びます。
それには大量のデータとコンピューターに関する知識、そして時間が必要だということは心に留めておいてください。
ニューラルネットワークは以下の2つを行うことができます。
- データベースに蓄積された解答のセットからの返答の選択
- 学習し、自ら回答を創出する
2番目のアプローチの方がより現実的に思える一方、多量のデータと厳密なテストが必要となります。
また、ニューラルネットワークは時に、おかしな反応をする可能性があります。
原文
https://chatbotslife.com/how-not-to-miss-the-chatbot-train-in-2017-704fb7460a23
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。
チャットボット選定で“絶対に外せない”3つの確認ポイントとは?
本資料(無料 eBook)をご覧頂ければ、以下の事がスムーズに出来る様になります。
- 選定候補のAIチャットボットを客観的に比較する事
- 実機トライアルで準備・確認すべき事
- 自社に最適なサービスを見つけ、失敗せずに導入する事