※操作手順の画面キャプチャ掲載
あらすじ
とりあえず、話題の機械学習とやらに触れてみたい!
ディープラーニングを最速で試してみたいが、プログラミング経験が無いので、とりあえず簡単にスグに動かせる環境が欲しい!
そんな方へ向けて、Jupyter Notebookを使用し、最速でディープラーニングをブラウザ上で実行出来る環境を構築する方法を解説していきます。
そして、実際に簡単な機械学習の処理をしてみるところまでお伝えいたします。
1. 作業環境
Windows10
2. Jupyter Notebookとは?
Jupyter Notebookとは、ブラウザ上で実行される、プログラムの対話実行環境となります。
対応している主要な言語(Julia + Python + R)からJupyterと名付けられました。
現在は上記のようなデータ分析系に主に用いられる言語だけでなく、他にも様々な言語をサポートします。
基本的な対象言語はPythonで、Jupyter Notebookを実行するには、Pythonのインストールが必須となります。
3. Jupyter Notebookのインストール方法
Pythonのセットアップを行った上で(Pythonのセットアップについては、ここでは割愛します。)、Jupyterプロジェクト本家のページからインストールを行う方法が一般的です。
また、Pythonのインストール・トラブルを無くす為、Jupyter Notebookインストール後に必要なライブラリ等を効率的に配備する方法等もお伝えしていきます。
Anacodaのインストール
Continuum Analytics社が提供している Python と conda というパッケージマネージャーを含む Python ディストリビューションの事を指しています。
Anaconda はデータサイエンスに特化したプラットフォームを提供したいというのが目的のようです。
そのため、その分野向けによく使われる一連のパッケージ群が同梱されているのが特徴になります。
また、Anacondaをインストールすると、Python、及びJupyter Notebookもインストールされるため、最も簡単な、Jupyter Notebookのインストール方法となります。
Anacondaのインストールは非常に簡単で、以下の本家のサイトより、Windows、Mac、Linuxそれぞれの環境に合わせて、必要なインストーラをダウンロードし、インストールします。
今回はPython3系をインストールする手順を解説致します。
4. インストール結果の確認
Anacondaのインストールが、特にエラーなども無く、無事に終了した場合、Jupyter Notebookも無事にインストールが完了しているはずなので、Jupyter Notebookを起動してみます。
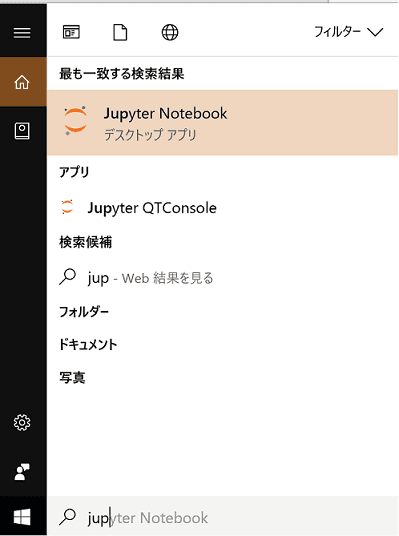
Windows10の場合、上記のようにスタート画面の検索欄に、jup 等と入力すると、Jupyter Notebookがインストールされていることが確認できるかと思いますので、クリックして起動してみます。
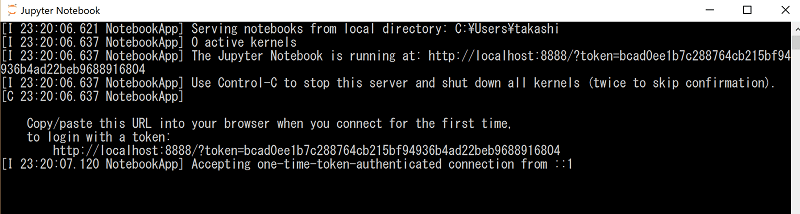
すると、上記のように、Jupyter Notebookが起動され、デフォルトのブラウザ上の localhost:8888/tree で、以下のようにJupyter Notebookのパスが閲覧出来る事を確認します。
(Windowsの場合、パスのルートは、ユーザのホームフォルダに設定されます。)
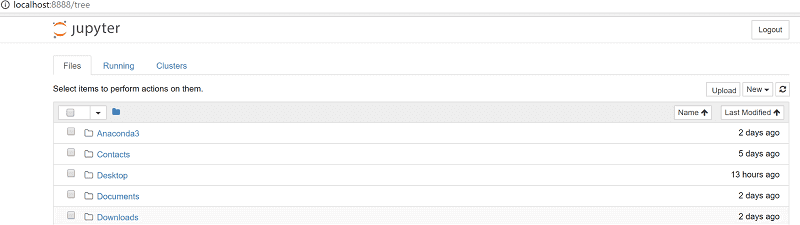
5. 作業フォルダと、Notebookの作成・実行
まずは、以下のように New をクリックし、Folderを選びます。
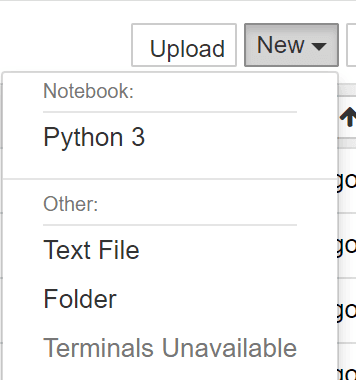
「Untitled Folder」が生成されるので、それを選択し、フォルダ名を workspace にリネームします。
その後、workspaceフォルダをクリックし、workspaceフォルダ配下に移動します。
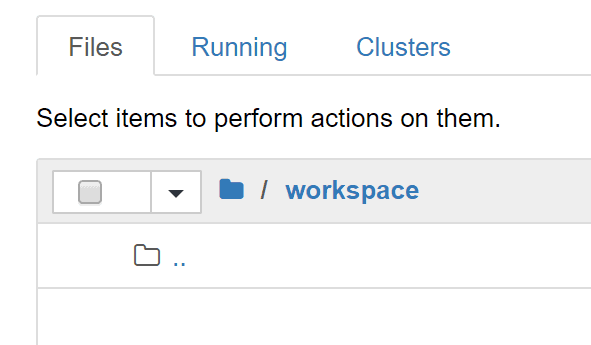
/workspace 配下に移動した事が確認できました。ここでまた New ボタンを押下して、Python3を選択します。
そうすると、以下のようにNotebookが生成されるので、そこで、定番の Hello world! を出力するコードを書いてみます。
print(“Hello world”)
というだけのコードですが、Jupyter Notebookには、コード補完機能も実装されているので、 pri とタイプして、tabキーを押すと、コード補完が可能です。
- コードを保存するには、Ctl + S
- コードを実行するには、Ctl + Enter
となります。以下のように Hello world! が出力されると、正しくプログラムが実行されています。
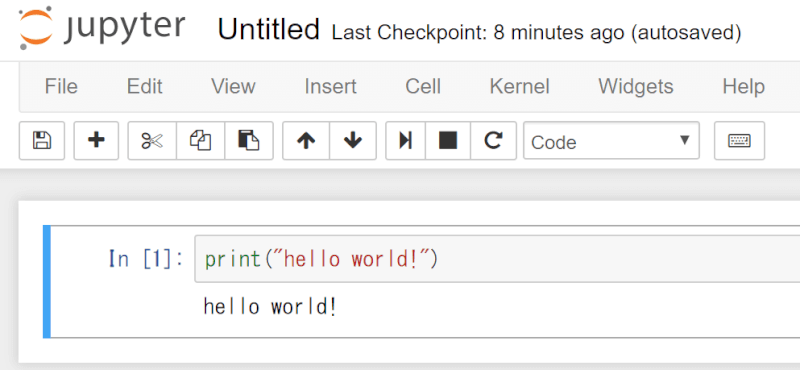
上記のソースファイルは、現在は Untitled となっていますが、これを任意の名前に変更する事は可能です。
Untitledの部分をダブルクリックし、 test 等、任意の名前に変換します。
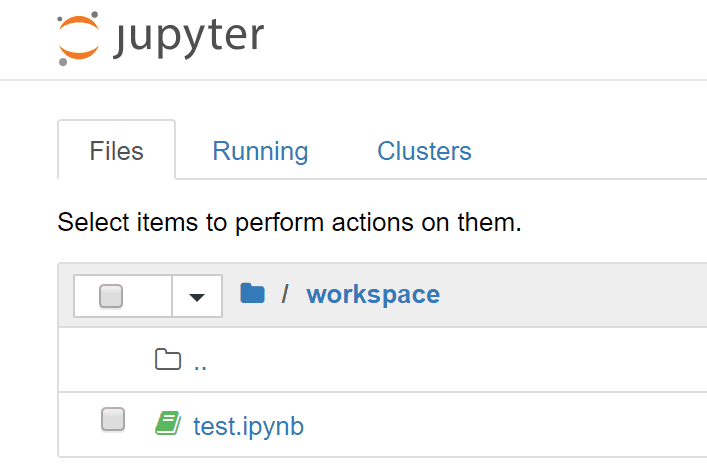
Workspace上に、test.ipynb ファイルが生成されているのが確認されます。
以上で、Notebookの作成と、実行が完了しました。
以降、もう少し詳細を見ていきます。
6. プログラム実行単位であるセルとは?
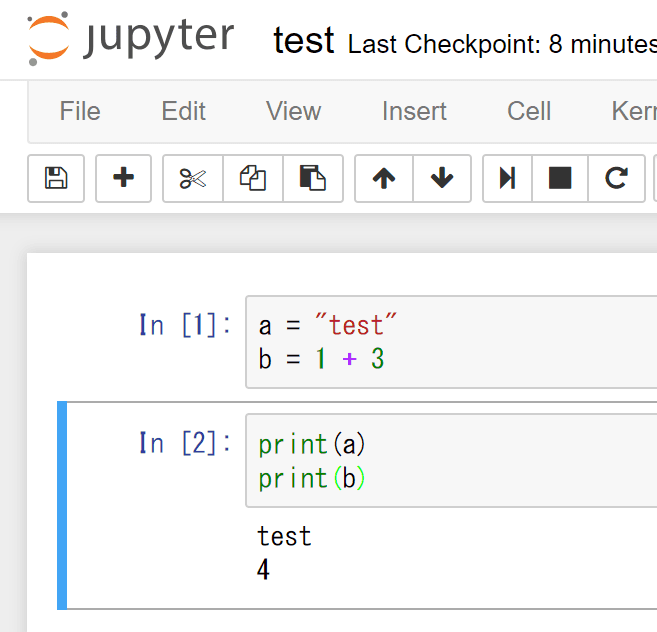
上記の、n[1] n[2] に当たるブロックはセルと呼ばれ、この単位ごとにプログラムが実行されます(セルの順番は関係ありません)。
上の場合では、n[2] で、n[1]の変数に格納した値の結果を出力する場合、n[1]をハイライトし、ctl + s、ctl + Enterにて、n[1]のセルを実行した後に、n[2]を実行する必要があります。
ここで重要なのは、いきなり n[2] を実行した場合は、変数が宣言されていないため、エラーが返る事となります。
ですので、必ず、n[1]から実行を行う必要があります。
一度変数に格納した値は、明示的にそれを破棄するまで、全セルで共通に参照できます。勿論、別のセルで値を上書きする事も可能です。
もし、変数に格納した結果や、実行結果等を全てリセットしたい場合は、以下のように Restart & Clear Output を選択すると、全てのセルの実行結果が初期化されます。
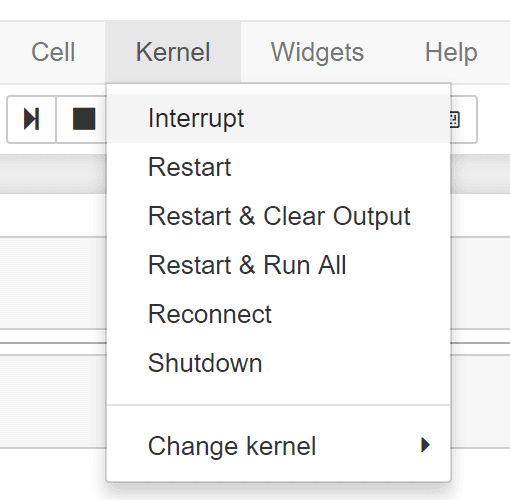
このように、Jupyter Notebookは、ブラウザから対話型で、非常に簡単にプログラムを実行でき、また、その結果を保存できます。
さて、それではお待ちかねの、機械学習を実行するプログラムの作成に進んでみましょう。
7. Jupyter Notebookからのscikit-learn使用方法
それでは、Jupyter Notebookから、Pythonの機械学習のライブラリとして有名な、scikit-learnを使用してみましょう。
ディープラーニング(MLP:多層パーセプトロン)を使用して、0から9までの数字の分類をするコードを実装してみます。
ここでは、scikit-learnや、ディープラーニングの詳細の説明は割愛させて頂きます。
(それらについては、リンクの記事をご参照下さい)
以下のコードと、その実行結果をご覧ください。
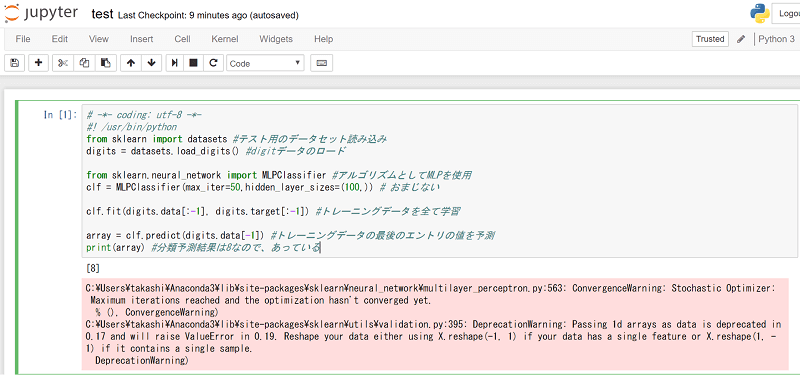
非常に簡単に、コードの説明をすると、
- Scikit-learnのデータセットから、数値データを読み込む
- 機械学習のアルゴリズムとして、ディープラーニング(MLP)を使用
- そのデータをトレーニングデータとして学習
- テストデータの結果(数字)を予測
という内容になっています。
これを、実行すると、予測結果は 8 となるので、学習が正しく行われた事がわかります(赤い箇所は、警告のメッセージなので、無視しても構いません)。
以上、Jupyter Notebookで、非常に簡単にディープラーニングを実行できた事が確認できたかと思います。
これならば、他にも色々試してみたくなりますね!