※サンプル・コード掲載
あらすじ
scikit-learnはpythonで使用できる機械学習ライブラリですが、元々とても多くの推定器(Estimator)が実装されています。
ただ、どのEstimatorを使えばよいのか最初から決めるのは経験則や広範囲な知識が必要なのでなかなか難しいです。
そのため、一括で全部試してしまってその結果から良さそうなモデルを選定していくという方法を取ると効率がよいため、その方法をご紹介します。
1. 環境構築
環境はpython3を使用します。
必要なライブラリをインストールします。
また、日本語の処理にmecabが必要なので、それもインストールします。
#数値計算・機械学習系
sudo pip install pandas
sudo pip install scikit-learn
sudo pip install scipy
#mecab
sudo apt-get install mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8
sudo pip install mecab-python3
sudo pip install nose
2. コーパスの準備
では分類するコーパスを用意しましょう。
今回はlivedoor ニュースをコーパスとして使用します。
こちらから通常テキストの方をダウンロードして下さい。
https://www.rondhuit.com/download.html#ldcc
ダウンロードしたファイルを解凍するとtextというフォルダができると思います。
各カテゴリごとにフォルダが分かれて記事が入っているため、このままだと扱いにくいためを1ファイルのcsvにします。
そのフォルダ内に下記のpythonファイルを置いて、実行して下さい。
# coding: utf-8
import os,os.path
import csv
f = open('corpus.csv', 'w')
csv_writer = csv.writer(f,quotechar="'")
files = os.listdir('./')
datas = []
for filename in files:
if os.path.isfile(filename):
continue
category = filename
for file in os.listdir('./'+filename):
path = './'+filename+'/'+file
r = open(path, 'r')
line_a = r.readlines()
text = ''
for line in line_a[2:]:
text += line.strip()
r.close()
datas.append([text,category])
print(text)
csv_writer.writerows(datas)
f.close()
corpus.txt
というファイルが出来たかと思います。
3. 全モデルで交差検定
3-1. 交差検定コードの記述
では、実際に全モデルでモデルを作成し、交差検定するコードを書いていきます。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from sklearn.utils.testing import all_estimators
from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import cross_val_score
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import MeCab
import sys
CROSS_VALIDATION_N = 4
wakati = MeCab.Tagger('-O wakati')
def tokenize(text):
'''テキストを形態素解析し、形態素の配列を返す'''
parsed_text = wakati.parse(text)
word_list = parsed_text.split(' ')
return word_list
def get_textdata_and_labels(_data):
df = pd.DataFrame(_data)
df.columns = ['text','category']
#テキストのBoW生成
count_vect = CountVectorizer(analyzer=tokenize,max_df=0.5, max_features=1000)
bow = count_vect.fit_transform(df["text"].tolist())
X = bow.todense()
# ラベルデータをベクトルに変換
le = LabelEncoder()
le.fit(df['category'])
Y = le.transform(df['category'])
return X,Y
import csv,io
def get_list_by_csv(file_path):
"""CSVから配列に変換を行う"""
csv_reader = csv.reader(
io.open(file_path, "r", encoding='utf_8'),
delimiter=",",
quotechar='"'
)
return [row for row in csv_reader]
def main():
_data = get_list_by_csv('corpus.csv')
X,Y = get_textdata_and_labels(_data)
for (name,Estimator) in all_estimators():
print(name)
model = Estimator()
if 'score' not in dir(model):
continue;
try:
scores = cross_val_score(model, X, Y, cv=CROSS_VALIDATION_N)
print(scores)
except:
print(sys.exc_info())
pass
if __name__ == '__main__':
main()
all_estimators()でscikit-learnに実装されている全モデルが取得できます。
ただし、scoreメソッドがないモデルはcross_val_scoreで交差検定ができないので今回は弾きます。
scores = cross_val_score(model, X, Y, cv=CROSS_VALIDATION_N)学習データをCROSS_VALIDATION_N等分に分けて、そのうちの1セットは学習に使わずにモデルの評価のために使います。
今回は4に設定しています。
get_textdata_and_labels(_data)ここでcsvのデータから、入力・出力のベクトルデータを生成しています。
その際に、入力が日本語なのでtokenize関数によって分かち書きした各単語を1hotベクトルにし、入力としています。
3-2. 実行結果の確認
実行してみると、下記のような結果が出力されると思います。
...
MultinomialNB
[ 0.53333333 0.53846154 0.7 0.7 ]
NMF
NearestCentroid
[ 0.6 0.61538462 0.5 0.7 ]
NearestNeighbors
Normalizer
NuSVC
[ 0.8 0.53846154 0.9 0.7 ]
...
モデル名とスコアが順番に出力されています。スコアはcv=4にしているので、通常0~1の間で4つ表示されます。
4等分したセットのうち1セット評価に使っているので、4つの結果が出ています。
このスコアのばらつきが少なく、スコアが高いモデルが良いモデルということになります。
ただし、それぞれのモデルはデフォルトパラメータを使っているので、結果が良かったモデル幾つかに対して、パラメータチューニングを行っていくと良いと思います。
4. パラメータチューニング
それぞれのモデルにはハイパーパラメータ(人間が指定する必要があるパラメータ)が幾つかあります。
ニューラルネットワークであれば層やユニットの数、活性化関数の種類。ランダムフォレストであれば決定木の本数等です。
ただここのパラメータの選択は経験が必要です。
経験があっても、トレーニングするデータによっても変わってくるので最初から一つに決めることはなかなか難しいです。
そこで、色々なパラメータを試してみてどのパラメータのセットが一番精度が高いかという検索を行いたいと思います。
やり方は2つあり、”グリッドサーチ”と”ランダムサーチ”があります。
4-1. ランダムサーチ
パラメータをなんらかの分布からランダムに取得し、そのパラメータをランダムに使って検索を行う方法です。
それぞれ下記のイメージを見てもらうと分かりやすいと思います。
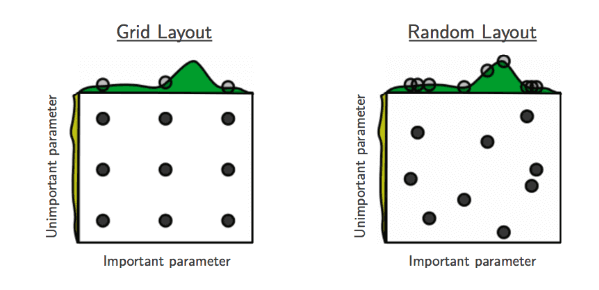
引用 http://www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdf
4-2. グリッドサーチ
予めパラメータをいくつか決めて、全通り試す方法です。
例えば、パラメータa,bの2つがあった場合、それぞれのパラメータで試す値を設定します。
上記の例だと3つずつ設定しているので、3×3=9通りの全パターンで検索が行われます。
今回はMLPClassifier(多層パーセプトロンのモデル)のグリッドサーチを例にチューニングを行ってみたいと思います。
調整出来るパラメータは多くありますが、その中でも次のパラメータを調整してみます。
- hidden_layer_sizes (隠れ層のニューロンの数)
- learning_rate (重みの学習率の更新の仕方)
- activation (活性化関数)
4-2-1. グリッドサーチのコード
from sklearn.grid_search import GridSearchCV
from sklearn.neural_network import MLPClassifier
def tuning():
_data = get_list_by_csv('../../sample_data/intent/faq.csv')
X,Y = get_textdata_and_labels(_data)
tuned_parameters = [
{'hidden_layer_sizes': [(100,),(200,),(100,100),(200,200)], 'learning_rate': ['invscaling', 'adaptive', 'constant'],
'activation': ['logistic', 'identity', 'relu', 'tanh']},
]
gsearch = GridSearchCV(MLPClassifier(max_iter=50), tuned_parameters, cv=4, scoring='accuracy', n_jobs=4)
gsearch.fit(X, Y)
print("ベストパラメータ:")
print(gsearch.best_estimator_)
print("各パラメータの平均スコア")
for params, mean_score, all_scores in sorted(gsearch.grid_scores_, key=lambda k: k[1],reverse=True) :
print("{:.3f} std:{:.3f} param: {}".format(mean_score, all_scores.std() , params))
tuned_parametersにて、どのパラメータを試すのかを指定します。
今回は上記のコードのように設定してみましたので、
hidden_layer_sizes 4通り × learning_rate 3通り x activation 6通り = 72通りのパターンを試してみることになります。
4-2-2. グリッドサーチの実行結果
各パラメータの平均スコア
0.884 std:0.041 param: {'learning_rate': 'constant', 'activation': 'relu', 'hidden_layer_sizes': (200, 200)}
0.884 std:0.037 param: {'learning_rate': 'constant', 'activation': 'logistic', 'hidden_layer_sizes': (100,)}
0.884 std:0.036 param: {'learning_rate': 'invscaling', 'activation': 'tanh', 'hidden_layer_sizes': (200, 200)}
0.884 std:0.039 param: {'learning_rate': 'adaptive', 'activation': 'logistic', 'hidden_layer_sizes': (100,)}
0.884 std:0.038 param: {'learning_rate': 'constant', 'activation': 'logistic', 'hidden_layer_sizes': (100, 100)}
0.884 std:0.039 param: {'learning_rate': 'constant', 'activation': 'tanh', 'hidden_layer_sizes': (200, 200)}
0.883 std:0.040 param: {'learning_rate': 'invscaling', 'activation': 'logistic', 'hidden_layer_sizes': (100, 100)}
0.883 std:0.038 param: {'learning_rate': 'adaptive', 'activation': 'logistic', 'hidden_layer_sizes': (100, 100)}
0.883 std:0.039 param: {'learning_rate': 'invscaling', 'activation': 'logistic', 'hidden_layer_sizes': (100,)}
0.883 std:0.040 param: {'learning_rate': 'adaptive', 'activation': 'tanh', 'hidden_layer_sizes': (100,)}
....
スコアの平均値が一番高いのは、0.884の時の6つのパラメータということがわかります。
ただ、stdはスコアの標準偏差なので、これが小さいほうがスコアのばらつきが少ないためより良いモデルなので、最適なのは
0.884 std:0.036 param: {'learning_rate': 'invscaling', 'activation': 'tanh', 'hidden_layer_sizes': (200, 200)}このパラメータの時だということがわかります。
ちなみにscikit-learnの公式ページにモデルの選択方法の図がありますので、こちらを参考に使えそうなモデルだけやってみるのもよいかと思います。
また、パラメータ設定方法に関して、詳しくは ニューラルネットワークのパラメータ設定方法(scikit-learnのMLPClassifier) をご参照頂ければと存じます。