※サンプル・コード掲載
チャットボットがどのように機能するのかを知ることはとても役に立ちます。
チャットボットの基本的な仕組みはテキスト分類器です。
アルゴリズム・アプローチの内部で働いている、多項分布モデル(Multinomial naive Bayes)を見てみましょう。
これはテキスト分類と自然言語処理(NLP)のための古典的なアルゴリズムです。
難しそうな名前ですが機能の仕方は比較的シンプルで一般的、そして驚くほど効果的です。
これは文章の「要素」がそれぞれ独立していると考える単純な分類器です。
この場合、要素とは単語です。
つまり分類される文章中の個々の単語は、互いに何の繋がりもないものとして扱われます。
例えば “The fox jumped over the log” という文章の中で、“jumped” と“fox” と “log”に何の関係もなくなります。
この単語の集合体は(NLPでは)’a bag of words‘と呼ばれています。
この驚くほど単純な分類器は文章の意味を理解しようとはしませんが、それを分類しようとします。
実際、どのチャットボットも人間の言語を理解しませんが、それは別の機会で話しましょう。
まず、テキスト分類器を1セクションごとに観察していきましょう。
以下のステップに従います。
- 必要なライブラリを参照
- トレーニングデータを用意
- データを整理
- 反復:コード化 + 必要なアルゴリズムをテスト
- 抽出する
コードはここにあります。
データサイエンスのプロジェクトにおいてとても効率的なiPython notebookを使います。
コードシンタックス はPythonです。
最初に自然言語ツールキットをインポートします。
# use natural language toolkit
import nltk
from nltk.stem.lancaster import LancasterStemmer
# word stemmer
stemmer = LancasterStemmer()NLTK(Natural language toolkit-自然言語ツールキット)を使う理由は2つあります。
- 文章を単語ごとに分解(トークナイゼーション)
“Have a nice day” なら“Have”“ a”“ nice”“ day”と個々の単語に分解する
- 単語を語幹に縮小(ステミング)
“have ”であれば“hav”とステミングし、“having”とマッチングするようにする(同じ語幹)
現在、複数の使用可能なステマーがありますが、ここではLancaster stemmerを使います。
次のステップではトレーニングデータを用意します。
トレーニングデータとしての数個の文章は、インテント(“class”)にカテゴリー分けされます。
例えばユーザーが“good day”と言ったら、“greeting”クラスに振り分けられるようにします。
# 3 classes of training data
training_data = []
training_data.append({"class":"greeting", "sentence":"how are you?"})
training_data.append({"class":"greeting", "sentence":"how is your day?"})
training_data.append({"class":"greeting", "sentence":"good day"})
training_data.append({"class":"greeting", "sentence":"how is it going today?"})
training_data.append({"class":"goodbye", "sentence":"have a nice day"})
training_data.append({"class":"goodbye", "sentence":"see you later"})
training_data.append({"class":"goodbye", "sentence":"have a nice day"})
training_data.append({"class":"goodbye", "sentence":"talk to you soon"})
training_data.append({"class":"sandwich", "sentence":"make me a sandwich"})
training_data.append({"class":"sandwich", "sentence":"can you make a sandwich?"})
training_data.append({"class":"sandwich", "sentence":"having a sandwich today?"})
training_data.append({"class":"sandwich", "sentence":"what's for lunch?"})
print ("%s sentences of training data" % len(training_data))アウトプットは以下の通りです。
12 sentences of training dataこれはリスト[]かディクショナリ{}だと気づかれると思います。
それぞれのディクショナリにはclassとsentenceの属性があります。
他の属性、例えばresponses等も簡単に追加でき、インテントが分類されたときにチャットボットが返信できるようになります。
これはアルゴリズムの内部の機能を見せるための最小限のデータです。
実用化には、それぞれが数個のトレーニング文章を持った何百個ものインテント(クラス)を作るかもしれません。
次のステップではアルゴリズムによって作動するようにデータを構造化します。
# capture unique stemmed words in the training corpus
corpus_words = {}
class_words = {}
# turn a list into a set (of unique items) and then a list again (this removes duplicates)
classes = list(set([a['class'] for a in training_data]))
for c in classes:
# prepare a list of words within each class
class_words[c] = []
# loop through each sentence in our training data
for data in training_data:
# tokenize each sentence into words
for word in nltk.word_tokenize(data['sentence']):
# ignore a some things
if word not in ["?", "'s"]:
# stem and lowercase each word
stemmed_word = stemmer.stem(word.lower())
# have we not seen this word already?
if stemmed_word not in corpus_words:
corpus_words[stemmed_word] = 1
else:
corpus_words[stemmed_word] += 1
# add the word to our words in class list
class_words[data['class']].extend([stemmed_word])
# we now have each stemmed word and the number of occurances of the word in our training corpus (the word's commonality)
print ("Corpus words and counts: %s \n" % corpus_words)
# also we have all words in each class
print ("Class words: %s" % class_words)アウトプットと私たちのトレーニングデータとの関連を見て下さい。
Corpus words and counts: {'how': 3, 'ar': 1, 'mak': 2, 'see': 1, 'is': 2, 'can': 1, 'me': 1, 'good': 1, 'hav': 3, 'talk': 1, 'lunch': 1, 'soon': 1, 'yo': 1, 'you': 4, 'day': 4, 'to': 1, 'nic': 2, 'lat': 1, 'a': 5, 'what': 1, 'for': 1, 'today': 2, 'sandwich': 3, 'it': 1, 'going': 1}
Class words: {'goodbye': ['hav', 'a', 'nic', 'day', 'see', 'you', 'lat', 'hav', 'a', 'nic', 'day', 'talk', 'to', 'you', 'soon'], 'sandwich': ['mak', 'me', 'a', 'sandwich', 'can', 'you', 'mak', 'a', 'sandwich', 'hav', 'a', 'sandwich', 'today', 'what', 'for', 'lunch'], 'greeting': ['how', 'ar', 'you', 'how', 'is', 'yo', 'day', 'good', 'day', 'how', 'is', 'it', 'going', 'today']}ステミングされた単語の集合体である「コーパス」(NLP用語)に注目してください。
一例として、makeの語幹はmakなので、makingとマッチングします。
次に、データを2つのディクショナリに整理します。
corpus_words(ステミングされた個々の単語と出現回数)とclass_words(個々のクラスと、その中のステミングされた単語のリスト)です。
私たちのアルゴリズムはこれらのデータを使って作動します。
次のステップでは、アルゴリズムをコード化します。最初のバージョンでは全ての単語を同等の重要度で扱います。
# calculate a score for a given class
def calculate_class_score(sentence, class_name, show_details=True):
score = 0
# tokenize each word in our new sentence
for word in nltk.word_tokenize(sentence):
# check to see if the stem of the word is in any of our classes
if stemmer.stem(word.lower()) in class_words[class_name]:
# treat each word with same weight
score += 1
if show_details:
print (" match: %s" % stemmer.stem(word.lower() ))
return scoreそれぞれの単語はトークン化、ステミング、そして小文字化されています。
これはコーパスデータによる変換と一致します。
つまり、私達のインプットデータはトレーニングデータと一致して変換されています。
# we can now calculate a score for a new sentence
sentence = "good day for us to have lunch?"
# now we can find the class with the highest score
for c in class_words.keys():
print ("Class: %s Score: %s \n" % (c, calculate_class_score(sentence, c)))“good day for us to have lunch?” を分類してみましょう。
match: day
match: to
match: hav
Class: goodbye Score: 3
match: for
match: hav
match: lunch
Class: sandwich Score: 3
match: good
match: day
Class: greeting Score: 2それぞれのクラスがマッチした単語数を表示しています。
次のステップに進む前に上記の例をよく理解しておきましょう。
個々の単語の一般性を考慮することにより、アルゴリズムを大幅に改良することができます。
多くの場合、“is” は“sandwich”よりも重要度が低いはずです。
なぜなら“is”はより一般的な単語だからです。
# calculate a score for a given class taking into account word commonality
def calculate_class_score(sentence, class_name, show_details=True):
score = 0
# tokenize each word in our new sentence
for word in nltk.word_tokenize(sentence):
# check to see if the stem of the word is in any of our classes
if stemmer.stem(word.lower()) in class_words[class_name]:
# treat each word with relative weight
score += (1 / corpus_words[stemmer.stem(word.lower())])
if show_details:
print (" match: %s (%s)" % (stemmer.stem(word.lower()), 1 / corpus_words[stemmer.stem(word.lower())]))
return score再度 ”good day for us to have lunch?” を分類してみましょう。
結果がかなり向上しました。
”day” と“ have”は(このコーパスでは)、より一般的な単語なので重要度のスコアが低くなり、正しいクラスに振り分けられるのに役立っています。
match: day (0.25)
match: to (1.0)
match: hav (0.3333333333333333)
Class: goodbye Score: 1.5833333333333333
match: for (1.0)
match: hav (0.3333333333333333)
match: lunch (1.0)
Class: sandwich Score: 2.333333333333333
match: good (1.0)
match: day (0.25)
Class: greeting Score: 1.25最終ステップではアルゴリズムを抽出し、シンプルに使えるようにします。
# return the class with highest score for sentence
def classify(sentence):
high_class = None
high_score = 0
# loop through our classes
for c in class_words.keys():
# calculate score of sentence for each class
score = calculate_class_score_commonality(sentence, c, show_details=False)
# keep track of highest score
if score > high_score:
high_class = c
high_score = score
return high_class, high_scoreいくつかサンプルを入力して分類器を試してみます。
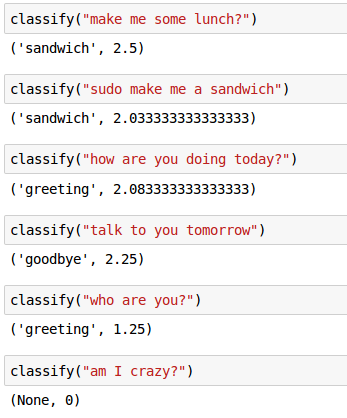
単純かもしれません、しかし驚くほど効果的です。

以前の記事を参考にし、このアルゴリズムを他のテキスト分類アプローチと比較してみてください。
原文
https://chatbotslife.com/text-classification-using-algorithms-e4d50dcba45
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。