※サンプル・コード掲載
1.AIに文章を作らせる方法概要
架空の名前から架空の人物の歴史概要を作成させてみました。
やり方としては、wikipediaの人物の概要の部分を抜き出してRNNにトレーニングさせます。
そのトレーニングさせたモデルに対して名前を入力すると、その人物の概要を出力してくれるようにします。
RNNとは、Recurrent Neural Networksの略で、時系列の情報を学習させるためのニューラルネットワークのモデルのことです。
文章を生成させるようなモデルの場合、多層パーセプトロンのようなモデルだと出力の長さが一定になってしまい、うまく作ることができません。
そこでRNNを使い、入力が単語(文字)、出力が次の単語(文字)として学習させると、そのモデルに次々と出力された単語を入力させることによって文章が生成出来るようになります。
そして、RNNは内部の重みを入力によって更新し、次の入力に備えます。
それによって、前の入力が例えば「僕/の/名前/は」と来たら、次に来るのは男性の名前であり、「私/の/名前/は」ときたら、女性の名前を出すようなモデルが作成出来るようになります。
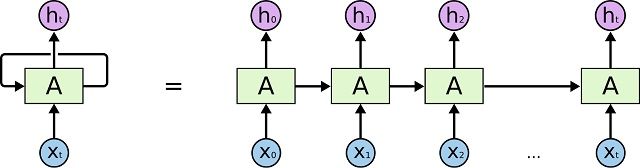
引用:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
また、学習時に終了フラグのようなものを定義して置くとそこで自動的に処理をストップさせることが出来るので、永遠に単語が出続けるということもありません。
ここで実際に使うのはLSTMという、RNNの進化版のようなモデルになります。
RNNは情報を長く記憶しておく事が不得意なので、単語を幾つか入力していくと過去の情報を忘れてしまいます。
先程の例で言うと、「私の名前はさやかです。最近は~~~ところで…」など長く入力していくと「ところで」をモデルに入力するタイミングでは、名前がさやか ということは忘れてしまっている可能性が高いということです。
この問題を解決したのがLSTMとなります。
2.環境構築方法
python3
必要なモジュールのインストール
mecab
sudo apt-get install mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8
pip install mecab-python3
3.AIライターの実装手順
まずwikipediaの概要を取ってくる必要がありますが、全ページクローリングするのは大変です。
そこで、dbpediaという便利なものがありますのでこれを使います。wikipediaの内容がデータベース上に入っており、SPARQLという言語でクエリを投げることができます。
今回は人物の概要が欲しいので、以下のクエリを投げます。
select distinct ?name ?abstract where {
?s a dbpedia-owl:Person .
?s rdfs:label ?name .
?s <http://dbpedia.org/ontology/abstract> ?abstract .
}
このクエリで全件ダウンロードしたいので、下記のpythonを用意しました。
import csv
from urllib.request import urlopen
import io
import os
f_write = open('ja.txt','w')
url = 'http://ja.dbpedia.org/sparql?default-graph-uri=http%3A%2F%2Fja.dbpedia.org&query=select+distinct+%3Fname+%3Fabstract+where+%7B%0D%0A++%3Fs+a+dbpedia-owl%3APerson+.%0D%0A++%3Fs+rdfs%3Alabel+%3Fname+.%0D%0A++%3Fs+%3Chttp%3A%2F%2Fdbpedia.org%2Fontology%2Fabstract%3E+%3Fabstract+.%0D%0A%7D%0D%0Aoffset+0%0D%0ALIMIT+10000&should-sponge=&format=text%2Fcsv&timeout=0&debug=on'
csv_text = urlopen(url)
cr = csv.reader(io.TextIOWrapper(csv_text))
row_count = 0
for row in cr:
row_count+=1
if row_count==1:
continue
f_write.write("<BOS>"+row[1]+"<EOS>\n")
BOS =Begin Of Sentence
EOS = End Of Sentence
の意味になります。後ほどモデルに食わせる時のためにこれらを文章の前後に付けます。
このコードだと10,000件しか取れないのですが、あまり多いと学習に時間もかかるため、今回は10,000人のユーザーから学習させてみます。
これで、ja.txtに人物の概要が1人1行で記載されたと思います。
ここでSPJのgithubを使用します。
git clone https://github.com/SPJ-AI/lesson
mv ja.txt lesson/text_generator/text/texts.txt
cd lesson/text_generator/
では準備が出来たらトレーニングを回しましょう。下記コマンドを実行して下さい。
python make_train_data.py
python train.py --batch_size=30 --epochs=50
トレーニングが完了したら下記を実行し、テキストを生成してみましょう。
python generate.py
※train.py,generate.pyの実行は、GPUが使用可能な場合は –gpu=0 のオプションを追加すると高速に実行可能です。
4.実行結果
-=-=-=-=-=-=-=-
酒井北郷(ないとうただまさのり)は、戦国時代の武将。下野巣北条氏の家臣。豊後の乱で夭逝した。
-=-=-=-=-=-=-=-
キム(モット・ザ・フープルあおきのぶいえ)は、下総関宿藩から続いた。寛政2年(1728年)8月16日死去で跡を継いだ。天明元年(1789年)死去。享年58。
-=-=-=-=-=-=-=-
美木ダイアリーピンクニー(りゅうおきょうともゆき)は、岡藩の第6代藩主。藤井松平家初代。
…
名前(ふりがな)、簡単な説明
という流れは記憶されている事がわかりますね。
今回は10,000件でしたので、件数を増やすともう少し良い結果になると思います。
また、次回の記事では性別・年齢・生まれた時代等のパラメータに応じて概要を変えてくれるようにしてみたいと思います。
貴重な投稿ありがとうございます!
generate.py で実行したところ、
————-
Traceback (most recent call last):
File “generate.py”, line 132, in
order_prob, next_prob, index = get_next_word_prob(model, “の”, “害悪”)
ValueError: need more than 2 values to unpack
でエラーになってしまいました。
結構時間をかけたんですが・・・残念です・・・
大変失礼致しました。
generate.pyのコードが正しく文章を生成するコードになっておりませんでした。
gitのソースコードを修正致しましたので最新版を落として頂ければと思います。
ご指摘ありがとうございます。
失礼いたします。
generate.pyを実行したところ
File “generate.py”, line 79, in get_next_word_prob
index = vocab[word]
というエラーがでてできませんでした。。。
残念です。。。
お返事遅くなりまして申し訳ございません。
エラーの内容が不明瞭なため、原因がわかりかねますが、
一部エラーを回避するようなコードを追加致しましたので、
最新のコードをgitからpullして頂き、再度実行してみて頂けますでしょうか。
P.S.
最近スパムコメントが多い為、コメント機能を一旦停止させて頂いている為、
次回、以下よりお問合せ頂ければと存じます。
https://spjai.com/company/contact/
宜しくお願い致します。