1.あらすじ
人工知能ブームがどんどん加速する中、ニューラルネット、SVM、ナイーブベーズ等、様々な機械学習の手法が存在し、その派生系もどんどん増えていって、一体どういう場合にどのアルゴリズムを選ぶといいんだろうと、首を傾げている方も多いと思います。
今回はその中でも、特にアンサンブル学習という手法を紹介します。
アンサンブル学習とは、その名の通り、簡単に言えば多数決をとる方法で、個々に別々の学習器として学習させたものを、融合させる事によって、未学習のデータに対しての予測能力を向上させるための学習です。
他の、回帰や分類を目的とした機械学習アルゴリズムとは、少し趣が異なる学習方法となっております。
また、アンサンブル学習の特徴は、単純にアンサンブル学習そのものを回帰や分類の機械学習のアルゴリズムの手法として用いるだけでなく、他の機械学習アルゴリズムの学習係数を求める際などに、補助的に用いられる等、その使い道は非常に幅広いものとなっております。
要するに、昔からの日本の諺のように、三人寄れば文殊の知恵という事です。
それでは、いかにアンサンブル学習の代表的な手法の解説と、そこで用いられる代表的なアルゴリズムについて紹介して参ります。
2.アンサンブル学習の有効性とは?
アンサンブル学習の仕組みの解説に進む前に、なぜ、アンサンブル学習が一般的に有効だと言われているかについて、簡単に解説をしておきます。
冒頭でも解説しましたが、アンサンブル学習の有効性は、弱学習器を使用して、多数決をとれることなのですが、これがどう有効になっていくか、もう少し詳細を見ていくことにします。
まず、単純に皆様が2値分類の分類問題に取り組んでいると仮定をした際に、通常の分類器で分類を行った場合は、当然その分類器が誤分類をした場合には誤った結果が返される事になります。
しかし、アンサンブル学習の場合は、多数決となるので、m個の学習器がある場合に、(m + 1) / 2 以上の学習器が誤判定をしない限り、正解という事になります。
そして、よく間違えやすい分類問題などでは、例えばニューラルネット、SVM、ナイーブベーズ等、複数の分類器の結果を真とできるため、非常に有効になります。
また、各弱学習器が、統計的に独立と仮定をして、弱学習器の誤差判定の確率を、一律θと仮定した場合は、m個の弱学習器のうち、k個が誤判定をする確率は以下となります。
![]()
式1
数式アレルギーの方は多いかもしれないですが、この式の意味を説明すると、単純にm個中、k個の弱学習器が間違うと、mの数が小さければ小さいほど、誤学習の率は低下するという事です。
ここまで、アンサンブル学習の有効性について解説して参りましたが、非常に直感的な説明であったと思います。
なぜアンサンブル学習が有効なのかについて、詳細な解析は未だにされていないというのが実情らしいですが、皆様の直感でも、アンサンブル学習が有効な事は理解できるのでは無いでしょうか?
3.バギングとは?
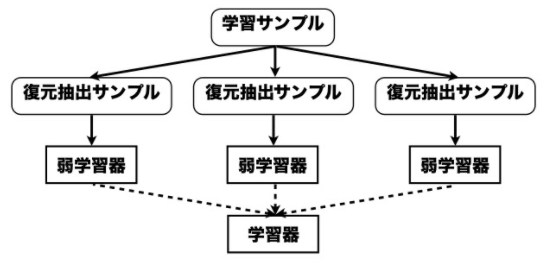
アンサンブル学習の主流な方法の1つであり、学習データの情報を全て使うのでなく、その一部を使用して学習し、最後に結合させる方法です。
それぞれが、別個に計算可能なため、並列処理が可能になります。
ブートストラップ法によって、弱学習器を選別し、最終的な学習器に合併する方法です。
引用:https://www.slideshare.net/holidayworking/ss-11948523
基本的な、バギングの方法は極めて単純で、以下の通りです。
1.以下の手順をB回繰り返す
a.学習データから、m回分割抽出をして、新しいデータセットを作る
b.その分割されたデータセットを元に、弱学習器hを構築
2.B個の弱学習器hを用いて、最終的な学習結果を構築
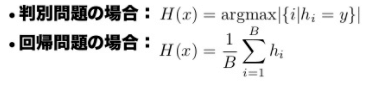
引用:https://www.slideshare.net/holidayworking/ss-11948523
その最終的な学習結果を硬直する部分の数式は上記ですが、判別、分類問題の場合は、それぞれの弱学習器の、全体としての精度が最高になるように選別、回帰の場合は、それぞれの弱学習器を、全体の値で正規化していく感じとなります。
バギングを使用した、有名な機械学習アルゴリズムの例としては、「ランダムフォレスト」等があげられます。
4.ブースティングとは?
学習データの一部を使用し、最後に合併させる部分はバギングと共通ですが、違いは、ブースティングは以前に使用したデータを再利用して、文字通りブーストする点であり、この理由によって、バギングのように並列処理は不可能となります。
ブースティングは、逐次的に弱学習器を構築していくアンサンブル学習のアルゴリズムで、有名な機械学習のアルゴリズムとしてはAdaBoost等があり、以下にAdaBoostの解説をしていきます。
AdaBoost
AdaBoostは、分類器の間違いに基づいて、それをフィードバッックとして、調整された次の分類器を作るという点で、適応的(Adaptive)であり、ノイズの多いデータや、異常値に影響を受けやすいという特性はありますが、AdaBoostが備える適応性のおかげで、うまく使用すると他の機器学習よりオーバフィットを抑えられるという特性があります。
AdaBoostは、学習データに対して、弱分類器を、t=1 から t=Tまで順に適用していき、それぞれが正解したかどうかを判定していきます。
この際に、間違って分類されたサンプルに対する重みを重く調整したり、逆に正解したサンプルに対する重みを減らしたりしながら、調整を行っていきます。
以下にAdaBoostを使用して、分類をする際のアルゴリズムを紹介いたします。
少し数式が多くなり、恐縮ですが、なるべく数式そのものよりも、大まかなイメージを解説していきますので、お付き合い頂ければ幸いです。
・1からnまでの間で、学習データのサンプルがあるとします。
![]()
・そのサンプルに対して、-1から、1をとる(2値を仮定)、正解データのサンプルがあるとします。
![]()
・1からnまでの各ウエイトの重みのデフォルトを、1/nとセットします。
![]()
・それぞれの学習サンプルに対する、弱学習器をhとします。
![]()
・t = 1 から Tの範囲で、弱学習器を、確率分布に基づいて剪定します。
![]()
・各時刻で、1時刻前の情報を用いて、弱学習器の誤り率(Et)を計算します。
この式でαは、弱学習器の重要度の値を指しており、このαも計算していきます。
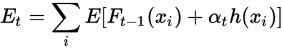
・上記の計算結果を用いて、全ウエイトを計算し直します。
![]()
重要度のαの算出方法の詳細や、誤り率の算出方法の詳細は、数式が複雑になるため割愛させて頂きました。
非常に簡単に、AdaBoostのアルゴリズムをまとめると、
- サンプルに対して、確率分布に基づいて、T個に分割した弱学習器を一列に並べ、
- 弱学習器の誤り率Eと、重要度αを逐次計算していき、
- 毎回、全体のウエイトを調整
そうする事で、どの時刻の弱学習器に対しても、最適な解を割り出せるように、調整を進めていく、ある種の動的計画法的なアプローチです。
少し複雑ですが、こういった理由からAdaBoostは、ディープラーニングをはじめとする、機械学習の学習係数の算出等に用いられ、良い成果が得られています。
また、この有用性が立証されているため、Gradient Boost等、色々な派生系も存在します。
こちらに関しても非常に興味深いので、また別の機会にご紹介させて頂きたいと考えております。