※サンプル・コード掲載
Tensorflow における本物のディープ・ニューラルネットワークの実装方法とは?
あらすじ
ニューラルネットワークの設計に関して言えば、数年前のトレンドは、“深さ”という一方向に向いていました。
ところが、たった数年前の最先端技術は、ざっと12階層の深さのネットワークからなっていました。
今では100階層の深さのネットワークを検討することも驚くべきものではありません。
この動きは単純により深くするために、深くなっていったわけではありません。
多くのアプリケーションにとって、中でも最も顕著なのは画像分類ですが、より深いニューラルネットワークは、より良いパフォーマンスが出たからです。
それらは適切に訓練することができるのです。
この記事では、最近の3つのディープラーニング・アーキテクチャ:ResNet、HighwayNet、そしてDenseNetの背後にあるロジックを読み解いていきたいと思います。
それらは従来のネットワーク設計の限界を克服することで、訓練可能なディープラーニングの実現を可能にします。
また、各それぞれのネットワークをより簡単に実装するためのTensorflowコードも提供します。
もし、コードだけが必要であればこちら で見つけることができますが、そうでなければ、是非読み進めてください!
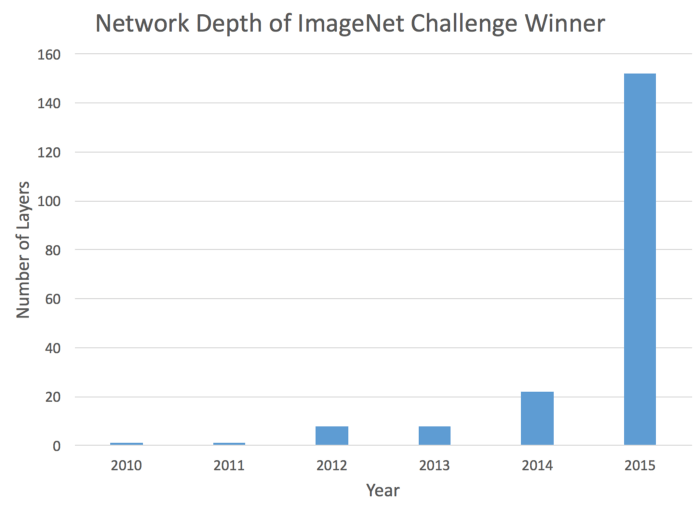
なぜ単純に階層を深くするだけでは機能しないのか?
ディープネットワークを設計する際の最初の直感は、おそらく畳み込み層等の典型的な構成要素の多くを単純にスタックすることです。
それはある点においては機能しますが、従来のネットワークがより深くなるとパフォーマンスは急速に低下します。
その問題は、バックプロパゲーション(backpropogation)によるニューラルネットワークの訓練方法が招きます。
ネットワークの訓練中、ネットワーク・アップデートが適切化されるために、シグナルはネットワークを通り最上層のレイヤーから最下層のレイヤーにまで伝達されなければいけません。
この従来のネットワークでは、勾配がインターネットの各レイヤーを通過する際に減少します。
わずかのレイヤーしか持たないネットワークにとって、これは問題ではありません。
しかし、数ダース以上のレイヤーを持つネットワークでは、どうしてもシグナルがネットワークのはじめに再び到達するまでに途絶えてしまいます。
そのため問題は、数ダース、あるいは数百の深さのレイヤーになりうるネットワークであっても、全レイヤーにシグナルがより簡単に届くようにデザインすることです。
これが、ResNets、HighwayNets、そしてDenseNetsという次の最先端アーキテクチャのゴールです。
Residual Network
Residual Network もしくはResNetは簡単な方法で勾配消失の問題を解決するニューラル・ネットワークです。
もし、シグナルの送信で問題が生じた場合、なぜ、よりスムーズに動作させるために各レイヤーにショートカットを設けないのでしょうか?
従来のネットワークにおいて、レイヤーのアクティベーションは以下のように定義されます。
y = f(x)ここでは、f(x) は畳み込み、行列乗算、バッチ正規化などです。
信号が逆方向に送られた時、勾配は常にf(x)を通過するでしょう。
代わりにResNetは以下を実装しています。
y = f(x) + x最後の“+ x”がショートカットです。
これによって勾配を直接送ることができます。
これらの層を積み重ねることによって、理論上、勾配は中間層を“スキップ”し、減少なしに最下層に達することができるのです。
これは直感ですが、実際に実行するにはもう少し複雑です。
ResNetsの最新版では、f(x) + x は以下の形式になっています。
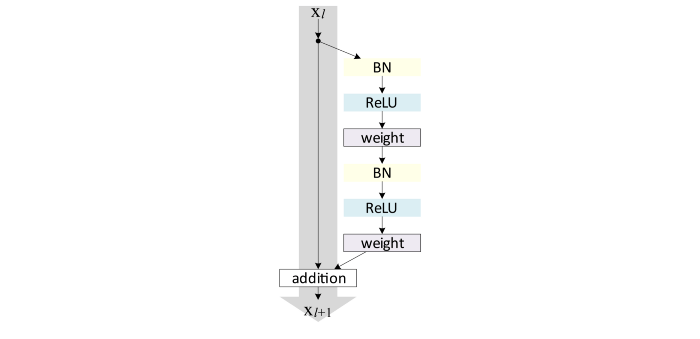
ResNetユニットアーキテクチャ。BN:Batch Normalization。Weightは完全接続もしくは畳み込みレイヤーを参照することができます。
Tensorflowを用いて、以下のようにResidualユニットから構成されているネットワークを実装することができます。
import tensorflow as tf
import numpy as np
import tensorflow.contrib.slim as slim
total_layers = 25 #Specify how deep we want our network
units_between_stride = total_layers / 5
def resUnit(input_layer,i):
with tf.variable_scope("res_unit"+str(i)):
part1 = slim.batch_norm(input_layer,activation_fn=None)
part2 = tf.nn.relu(part1)
part3 = slim.conv2d(part2,64,[3,3],activation_fn=None)
part4 = slim.batch_norm(part3,activation_fn=None)
part5 = tf.nn.relu(part4)
part6 = slim.conv2d(part5,64,[3,3],activation_fn=None)
output = input_layer + part6
return output
tf.reset_default_graph()
input_layer = tf.placeholder(shape=[None,32,32,3],dtype=tf.float32,name='input')
label_layer = tf.placeholder(shape=[None],dtype=tf.int32)
label_oh = slim.layers.one_hot_encoding(label_layer,10)
layer1 = slim.conv2d(input_layer,64,[3,3],normalizer_fn=slim.batch_norm,scope='conv_'+str(0))
for i in range(5):
for j in range(units_between_stride):
layer1 = resUnit(layer1,j + (i*units_between_stride))
layer1 = slim.conv2d(layer1,64,[3,3],stride=[2,2],normalizer_fn=slim.batch_norm,scope='conv_s_'+str(i))
top = slim.conv2d(layer1,10,[3,3],normalizer_fn=slim.batch_norm,activation_fn=None,scope='conv_top')
output = slim.layers.softmax(slim.layers.flatten(top))
loss = tf.reduce_mean(-tf.reduce_sum(label_oh * tf.log(output) + 1e-10, reduction_indices=[1]))
trainer = tf.train.AdamOptimizer(learning_rate=0.001)
update = trainer.minimize(loss)Highway Networks
次に私が紹介したいアーキテクチャは、Highway Networks です。
それは素晴らしく直感的な方法でResNet上に成り立っています。
Highway Networks は、ResNetで紹介したショートカットを保存します。
しかし、各レイヤーの範囲がスキップ接続か非線形接続かを判断するために、それらのショートカットに学習可能なパラメータを追加するのです。
Highway Networks のレイヤーは以下のように定義されます。
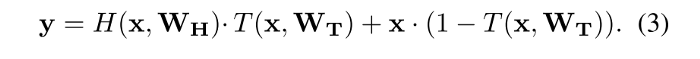
この方程式では、前に説明した2種類のレイヤーの概要を確認することができます。
y = H(x, Wh) は私たちの従来のレイヤーを反映し、y = H(x, Wh) + x は、Residual unitを反映しています。
新しいT(x, Wt)関数は何を意味するのでしょうか。
これは、プライマリパスもしくはスキップパスを介してどの程度の情報が送れられるべきかを判断するスイッチのような役割を持ちます。
2つの経路にT と(1-T)を用いることによって、アクティベーションは常に1になるはずです。
Tensorflowには以下のように実装することができます。
import tensorflow as tf
import numpy as np
import tensorflow.contrib.slim as slim
total_layers = 25 #Specify how deep we want our network
units_between_stride = total_layers / 5
def highwayUnit(input_layer,i):
with tf.variable_scope("highway_unit"+str(i)):
H = slim.conv2d(input_layer,64,[3,3])
T = slim.conv2d(input_layer,64,[3,3], #We initialize with a negative bias to push the network to use the skip connection
biases_initializer=tf.constant_initializer(-1.0),activation_fn=tf.nn.sigmoid)
output = H*T + input_layer*(1.0-T)
return output
tf.reset_default_graph()
input_layer = tf.placeholder(shape=[None,32,32,3],dtype=tf.float32,name='input')
label_layer = tf.placeholder(shape=[None],dtype=tf.int32)
label_oh = slim.layers.one_hot_encoding(label_layer,10)
layer1 = slim.conv2d(input_layer,64,[3,3],normalizer_fn=slim.batch_norm,scope='conv_'+str(0))
for i in range(5):
for j in range(units_between_stride):
layer1 = highwayUnit(layer1,j + (i*units_between_stride))
layer1 = slim.conv2d(layer1,64,[3,3],stride=[2,2],normalizer_fn=slim.batch_norm,scope='conv_s_'+str(i))
top = slim.conv2d(layer1,10,[3,3],normalizer_fn=slim.batch_norm,activation_fn=None,scope='conv_top')
output = slim.layers.softmax(slim.layers.flatten(top))
loss = tf.reduce_mean(-tf.reduce_sum(label_oh * tf.log(output) + 1e-10, reduction_indices=[1]))
trainer = tf.train.AdamOptimizer(learning_rate=0.001)
update = trainer.minimize(loss)Dense Networks
最後にDense Networks、つまりDenseNetをご紹介したいと思います。
ここでのアイディアは、もし前のレイヤーとスキップ接続で接続することによってパフォーマンスが向上するならば、どうしてレイヤーをその他の全てのレイヤーに接続しないのか?、というものです。
この方法では、常にネットワークを介したインフォメーション送る直接的なルートが存在することになります。
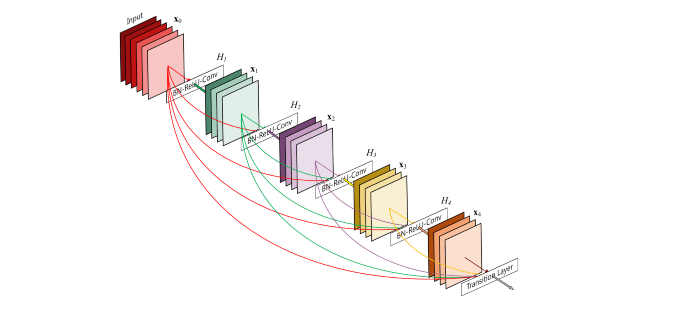
追加を行う代わりに、DenseNetはレイヤーのスタック(積み重ね)に依存します。
数学的には次のようになります。
y = f(x,x-1,x-2…x-n)このアーキテクチャはフィードフォワードとフィードバック両方で直感的に理解することできます。
フィードバック設定においてタスクは高レベルの機能のアクティベーションに加えて、低レベルの機能のアクティベーションも得られるというメリットがあります。
例えば、オブジェクト分類において、ネットワークの低レイヤーが画像内のエッジを判定するのに対し、高レイヤーが顔などのより大きな範囲を判定します。
複雑なシーンでは正しく対象を判定するのにエッジの情報が役に立つケースがあります。
フィードバックのケースでは、接続された全てのレイヤーを持つことは、ネットワーク内の特定の場所に勾配を素早く送信することをより簡単にします。
DenseNetsを実装する時、全てを単純に接続することはできません。
同じ高さと幅をもつレイヤーのみをスタック(積み重ね)することができるのです。
そのため、代わりに畳み込みレイヤーのセットを密にスタックしていき、その後convolutional layers、pooling layerを適用、さらにその後他の畳み込みレイヤーのセットを密にスタックしていくなどするのです。
これはTensorflowに以下のように実装することができます。
import tensorflow as tf
import numpy as np
import tensorflow.contrib.slim as slim
total_layers = 25 #Specify how deep we want our network
units_between_stride = total_layers / 5
def denseBlock(input_layer,i,j):
with tf.variable_scope("dense_unit"+str(i)):
nodes = []
a = slim.conv2d(input_layer,64,[3,3],normalizer_fn=slim.batch_norm)
nodes.append(a)
for z in range(j):
b = slim.conv2d(tf.concat(3,nodes),64,[3,3],normalizer_fn=slim.batch_norm)
nodes.append(b)
return b
tf.reset_default_graph()
input_layer = tf.placeholder(shape=[None,32,32,3],dtype=tf.float32,name='input')
label_layer = tf.placeholder(shape=[None],dtype=tf.int32)
label_oh = slim.layers.one_hot_encoding(label_layer,10)
layer1 = slim.conv2d(input_layer,64,[3,3],normalizer_fn=slim.batch_norm,scope='conv_'+str(0))
for i in range(5):
layer1 = denseBlock(layer1,i,units_between_stride)
layer1 = slim.conv2d(layer1,64,[3,3],stride=[2,2],normalizer_fn=slim.batch_norm,scope='conv_s_'+str(i))
top = slim.conv2d(layer1,10,[3,3],normalizer_fn=slim.batch_norm,activation_fn=None,scope='conv_top')
output = slim.layers.softmax(slim.layers.flatten(top))
loss = tf.reduce_mean(-tf.reduce_sum(label_oh * tf.log(output) + 1e-10, reduction_indices=[1]))
trainer = tf.train.AdamOptimizer(learning_rate=0.001)
update = trainer.minimize(loss)それら全てのネットワークはCIFAR10データセットを用いて、画像分類するようにトレーニングをすることができ、またそれは、従来のニューラル・ネットワークが失敗する多くのレイヤーを用いても良いパフォーマンスを発揮することができます。
少しのパラメータのチューニングで、たった1時間後にはテストセットにおいて90%以上の正確さを達成することができました。
それぞれのモデルのトレーニング用のコード、そして従来のネットワークと比較したものはこちら でご確認頂けます。
この記事がディープ・ニューラルネットワークの世界にとって役立つものであることを願っています。
原文
https://chatbotslife.com/resnets-highwaynets-and-densenets-oh-my-9bb15918ee32
チャットボットライフとの提携により、翻訳し掲載しています。
チャットボットライフとは、最新のボット、AI、NLP、ツール等を扱うメディアです。