1.あらすじ
Siriや、Google音声アシスタント等、音声アシスタントアプリケーションは、すっかりと日常生活に浸透し、実際に使用している読者の方も多いかと思います。
使用された方はお気づきかと思いますが、そういったアプリの音声認識の精度はかなり素晴らしく、十分実用に達しています。
また、音声アシスタントだけでなく、ミーティング時の議事録の自動作成や、ロボットとの対話等幅広い分野で利用されており、また日々その精度も向上してきています。
今回は、そんな音声認識技術に関して、どのような仕組みでそれが実現されているかについて解説して参ります。
2.音声認識とは?
それでは、一番最初に「音声認識」とは何か? について解説をしてまいります。
冒頭の例で、Siriや、Google音声アシスタントという言葉を出しましたが、これらのアプリケーションを音声認識アプリと思っている方は多いかと思います。
実際に、Siriや、Google音声アシスタントでは、音声認識は使われていますが、それはあくまで技術の一部であって、それらは音声認識アプリでは無く、音声アシストアプリと呼ばれるのが正解となります。
また、大流行した初音ミクのように、機械に発話させる技術は、音声合成と呼ばれ、音声認識とは区別されています。
それでは音声認識は何をする技術かというと、人間の会話の音声を認識して、それをテキストに変換する技術の事です。
Siriに向かって何か話しかけると、それが認識されてテキストに変換されている様子が確認できるかと思います。それが、まさに音声認識です。
3.現在の音声認識の精度
それでは、現在の音声認識の精度はどのくらいなのでしょうか?
勿論、Appleが開発している音声認識、Googleが開発している音声認識の間の精度は変わってきます。
また、一色単に音声認識といっても、その対象が会議などの割と公的な内容が対象の時もあれば、口語調のくだけた内容が対象になる事もあります。
ですので、厳密な意味での音声認識の精度を定義するのは難しいのですが、
- 会議などフォーマルな内容でゆっくり、はっきりわかりやすく発音している場合は、十分に実用レベル
- 日常生活の雑談等のくだけた表現が多用される場面では、半分程度の認識精度
といったところでしょうか。
近年、いわゆるディープラーニングが、音声認識の精度を飛躍的に向上させる等、音声認識分野に劇的な変化をもたらしており、今後、音声認識の精度はますます向上していくと思われます。
また、純粋な音声認識の精度向上とともに、雑談に特化して精度を向上させたり、機会に合わせて音声認識の精度向上をする動きや、個人の発音の癖や、個人の趣向を優先させる音声認識方法の研究等、様々な努力がなされており、多方面からの精度向上が期待できます。
4.音声認識の仕組み
それでは、音声認識の仕組みについて、具体的に解説をして参ります。
音声認識を実現する上で、まず欠かせないないのは「音声」とは何か?を知ることです。
4-1.音声とは?
音声とは何か?そもそもそういった事を、普段の会話の中で意識する機会そのものが無いと思いますが、音声とは以下の図で示す「調音器官」を複雑に使いながら、発せられるものです。
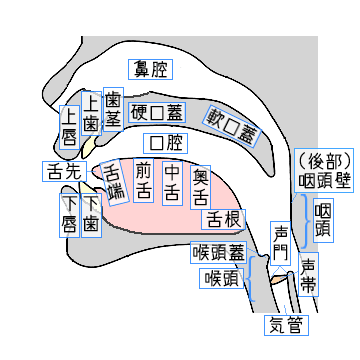
また、発生された音声は、勿論目には見えませんが、以下のような音波として表現されます。

音声認識技術では、この音波から、音の最小構成単位である「音素」を特定し、それを手がかりにしてテキストに変換する技術です。
「音素」とは、以下の単位から構成されます。
- 母音 アイウエオ
- 撥音 ン
- 子音 23種類
「おはよう」を音素に変換すると、o – h – a – y – o – u となり、このアルファベット一文字ずつの単位が音素となります。
4-2.音声認識技術の詳細
それでは、更に踏み込んで、音声認識技術の仕組みについての解説を進めて参ります。
音声による解説を行い、音を構成する最小単位である、音素についての説明をしましたが、音声認識技術は、その音素を認識して、テキストに変換していく技術です。
具体的な手順を示すと、以下のようになります。
- 音声入力
- 入力された音声を、音波に変換
- 音波から音素を特定
- 音素の並びを、予め登録した辞書とマッチングを行い、単語に変換
- 変換された文章をテキストで出力
1~3までの、音声を入力し、それを音波にし、そこから音素を特定するまでは既に詳しく解説したので、特に大きな疑問点は無いかと思いますが、4と5の作業のイメージが沸かないという方は多いかと思います。
ですので、そこを少し詳しく解説しておきます。
辞書とのマッチングという意味は、音声認識の仕組みの1つで、音素の並びと、それに対応した単語を以下のような構造で辞書として、保有しています。
| 音素 | 単語 |
| o-h-a-y-o-u | おはよう |
| o-h-a-y-o-n | おはよん |
| o-h-a | おは |
「おはよう」という入力は、o – h – a – y – o – u という音素の繋がりで表現される事は説明しましたが、音素を前方より1つずつ追いかけていくと、o-h-a-y-o-u が完全一致し、それに対応する単語である、「おはよう」を紐解く事ができます。
これが音声認識に使用されるパターンマッチの処理の概要であり、音声認識のテキスト変換処理の理論の基礎になっています。
5.パターンマッチに使用される辞書の構造
さて、前項で音声認識にはパターンマッチ用の辞書が必要になる事についてはお話しましたが、それでは、その辞書はどのような構造にすべきでしょうか?
先ほどはわかりやすく説明するために、テーブル構造のように辞書を表現しましたが、実際は前方から音素を1つずつ探索していく形になるので、それを探索しやすい構造で保持しておく事が大事になります。
例えば、「おはよう」「おはよん」「おは」の3つの単語では、共通の音素の要素があり、それらを探索する場合は、同じ経路を通る事になるので、共通の音素の部分をうまくまとめる工夫が必要そうです。
通常、このように共通部分をまとめる構造を、ネットワーク構造といい、それは以下のように実現されます。
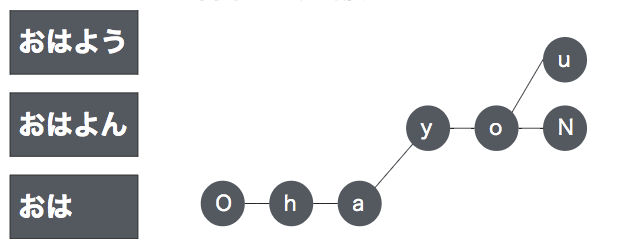
上の図のように、音素をノードで表現して、共通のものは共通のノードに集約されるように、ネットワーク構造を表現します。
通常、Trie木等の木構造のデータ構造が用いられる事が多いです。
このように、辞書の構造を工夫してやる事で、パターンマッチングの探索の速度の効率を上げる事ができます。
また、理解を簡単にするため、前項目で、前方探索でパターンマッチをする方法について解説しましたが、他にも後方探索等、様々な探索方法があります。
また、音声を音素に変換する部分の精度が、常に完璧になるわけではなく、音素への変換で認識ミスが起こる可能性も十分あるので、単語に変換する際に、もっともそれらしい単語を選ぶ必要があります。
6.文章の探索方法(隠れマルコフモデル等)
実際に音声認識を使う際には、議事録の収録などの用途に使われる事があり、先ほどの例のように短い単語に向けて使われる事よりは、それなりの長さの文章に対して使われる事が多くなります。
先ほどのように、音素を利用して、単語を探索するだけでなく、その単語と後の単語の繋がり等を考えていかなければなりません。
下の図をご覧下さい、こちらを言語モデルといいます。
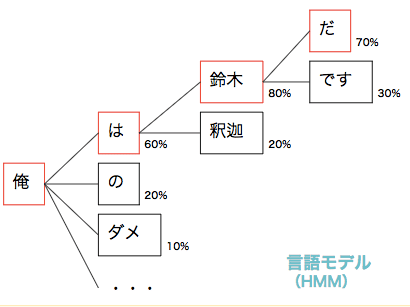
簡単にこの図を説明すると、ある単語の状態から、次の単語に移動する際に、どの位その繋がりの確率が起こるのかを定義しています。
「俺は」という文章がある時に、「俺は鈴木・・・」と続く確率の方が、「俺は釈迦」と続く確率よりも高いという事が言えます。
このように、現在の状態から次の状態に遷移する確率を定義するモデルを、HMM(隠れマルコフモデル)といい、現在の音声認識で非常にポピュラーに使われている方法です。
最近はその座をいわゆるディープラーニングに奪われつつありますが、未だにHMMはパワフルで、ディープラーニングと組み合わせる事によって、その精度を劇的に向上させる事も可能になるなど、未だに様々な可能性を秘めています。
音声認識を行うためには、このような言語モデルを構築する必要があります。
それを駆使して、単語と単語の繋がりを正しく認識してやる必要があります。
また、このようにして言語モデルを構築した後に、この確率モデルに基づいて、ある単語の次に取り得る単語を予測し、最もそれらしい文章を組み立てる方法を、ビタビアルゴリズム(Viterbi Algorithm)といい、最尤のパスを決定する、動的アルゴリズムの一種です。
この部分が、テキスト変換の精度に大きな影響を与えるので、ビタビアルゴリズムだけでなく、他のアルゴリズムも組み合わせる等、様々な工夫がなされています。
ビタビアルゴリズムに関して詳しくは、ビタビアルゴリズム【入門】具体例で分かりやすく解説! をご参照下さい。