1.あらすじ
Googleや、Yahoo検索等は、日常のネットライフには切り離せない存在になり、検索エンジンの存在しないネットサーフィン等、殆ど有り得ないかと思います。
そのくらい、今やすっかり日常に馴染んだ検索エンジンですが、最近では、AI技術と組み合わせる事でより高度になってきています。
ユーザの質問の意図を解釈する、意図解釈型の検索エンジンもメジャーになってきており、対話アシスタントや、対話システム等でも使用され、これからのAI市場を切り開く技術としても、大きな注目を集めています。
今回は、情報検索の仕組みを解説する事により、検索エンジンの仕組みを、わかりやすくお伝えする事を目的とします。
2.検索エンジンの種類
検索エンジンといってもその種類は様々であり、目的によって、それぞれの検索エンジンを適切に使用する事が重要になります。以下に代表的な検索エンジンの例を示します。
ロボット型検索エンジン
与えられた条件式によって、Webページ等を検索する検索サーバの事を指します。
基本的に「キーワード検索」により、検索を行い、単一のキーワードに対する検索だけでなく、複数のキーワードに対して、AND OR等の論理式を適用して検索を行う事が可能になるものです。
特徴としては、クローラ(Webスパイダー)を使用する事で、Web上に無数に存在する、Webページのインデックスを行い、効率よく検索できるような仕組みを提供しています。
最もエンドユーザへの馴染みが深い検索エンジンです。
ディレクトリ型検索エンジン
人手で構築をしたWebディレクトリ内を検索するシステムの事を指しています。
人手で構築されているために、文章のカテゴリ分け等の処理がしっかりと施されている事が多く、質の高い文章が検索可能です。
目的を絞った場合には、非常に精度の高い検索ができる事が知られていますが、人手による構築が前提なため、文章の数自体が多くできない、等の欠点があります。
メタ検索エンジン
入力された検索キーワードを、複数の検索サーバに送信し、得られた結果を表示するタイプの検索エンジンです。
横断型検索エンジンとも呼ばれ、メタサーチという呼び方が、一般的な用語となっています。
他にも様々な検索エンジンの種類がありますが、一番メジャーな形は、Google等のようなWebの検索を対象とした、ロボット型の検索エンジンと言う事ができるでしょう。
ロボット型検索では、与えられた文章群に対して、キーワードの論理式を用いて検索を行う、「全文検索」と言われる検索方法がメジャーになっています。
3.全文検索の3つの仕組みとは?
それでは、検索エンジンのエンジンとなっている、「全文検索」についての説明を進めて参りましょう。
今の情報検索で最も主流な形式は「索引(インデックス)型」と呼ばれており、検索対象になっている文章群に対して、高速な検索が可能になるような前処理を施します。
この検索対象の文章群に対して行う、前処理の事をインデッキシングと言い、その結果生成されるデータがインデックスです。
インデックスの構造には、文字列、ファイルへのリンク情報、更新日時等の情報が付与されて保存されます。
ここをもう少し深く掘り下げて、具体的に文章からどんな文字列を抽出して、インデックスファイルに保存をするのか、その方法を詳しく解説して行く事とします。
まずは話を分かりやすくするため、インデックスファイルの構造から説明していきます。
転置ファイル(inverted index)
検索エンジンの検索を高速化するために、文章中に現れる文字列と、その文章のID(文章を識別できるもの)をまとめるようにし、以下のような形式で構成されます。
| 単語 | 文章ID |
| 検索 | 1, 2, 3, 5 |
| 情報 | 1, 5, 6 |
| アルゴリズム | 2, 6, 8 |
表1.転置ファイル例
このような形式で転置インデックスを保存しておく事により、インデッキシングの際や、文章の検索の際に、二分木探索のアルゴリズムや、その他のアルゴリズムを用いる事によって、高速に文章を検索する事が可能になります。
次に、「では実際どのように、文章中の単語を抽出すればいいんだ?」という疑問が湧いてきたと思うので、以下、文字列抽出の方法について詳しく見ていく事にします。
1.n-gram法
「Nグラム法」等と呼ばれる、単純ですがパワフルな文字列分割アルゴリズムで、Nで指定した単語の長さに、先頭から1文字ずつ文字列を分割します。
例)N=2の時、「情報検索」という文字列に対して、N-gramを実行した例
情報 報検 検索 索
このように、文字列を分割する事で、「情報」と「検索」の単語が正しく抽出されるため、単語の抽出の取りこぼしを防げます。
しかしながら、この方法では、「報検」等の要らない単語によるノイズも多くなってしまい、それが検索精度に悪影響を及ぼす事もあります。
例えば、「東京都」という文字列に対して、「京都」でもヒットしてしまうようになるので、こういった例がn-gramの弊害として挙げられます。
また、特別にN=1の時がユニグラム、N=2の時がバイグラム、N=3の時がトリグラムと呼ばれます。
2.形態素解析法
現在の日本語の全文検索において、最もオーソドックスな方法です。
形態素解析とは何かというと、文字列を、単語の最小の構成単位に「分かち書き」する技術で、情報検索分野だけでなく、全ての自然言語処理分野の基礎モジュールとして、幅広い分野で使用されています。
英語の場合は、基本的には単語と、単語の間に空白があるため、割と簡単に形態素解析ができます。
英語の形態素解析の例
My name is Sato -> My|name|is|Sato
ところが日本語の場合は、こういった空白等が無いため、形態素解析の敷居は一般的には上がります(勿論、日本語には無い英語特有の形態素解析の悩みもありますが。。。)。
日本語の場合、形態素解析を実装するには、それ用の辞書が必須となり、何らかの機械学習のアルゴリズム等を使用して、前後の文脈等のコンテキスト情報を加味した分かち書きの仕組みを実装します。
代表的な形態素解析器はMeCab、Kuronoji等、オープンソースで提供されており、無償で使用する事ができます。
これらの形態素解析器は、精度も非常に高く、業界で幅広く用いられていますが、万能という訳ではありません。
辞書に登録の無い単語の分かち書きがうまくできなかったり、辞書が細かすぎるために、複合語をそのまま分かち書きできなかったりします。
この様な形態素解析特有の弊害が、情報検索の精度にも影響を与える事があります。
以下は日本語の形態素解析の例です。
日本語の形態素解析の例
情報検索は凄い → 情報|検索|は|凄い
上記の例で、「情報検索」を「情報」「検索」とそれぞれ分かち書きするか、1つとして抽出するかは、辞書によって結果が変わってきます。
「情報」「検索」と分かち書きされた場合は、それをれの単語を含む、「情報検索」以外の単語でも検索がヒットするようになります。
(「情報アドミニストレータ」という単語で検索しても、ヒットし得る。)
また「情報検索」と分かち書きされた場合は、「検索」という単語で検索をしてもヒットはしません。
検索の精度を向上させるには、このさじ加減をうまく調整する事が非常に大切になってきます。
3.ハイブリッド法
上記で、n-gram、及び形態素解析の強み・弱みについて解説を行いましたが、それぞれの弱点をカバーする方法として、これらを組み合わせて使用する方法もあります。
ただこの場合は、処理として非常に重くなってしまうので、適宜、状況に応じて適切な方法を切り替えて使用する方法が適切だと考えています。
具体的には
- 辞書に登録のない、専門用語等を取りこぼしなく抽出する(製品名、薬品名等)→ n-garam
- 一般的なWeb検索用の検索エンジン → 形態素解析
等、用途に応じて使い分けると良いと思います。
4.ユーザの問い合わせ(クエリ)と応答方法
さて、今まで、検索エンジンの仕組みの核であるインデッキシングと、その際に単語抽出に使用される、自然言語処理技術の要でもある、形態素解析についてのお話をしました。
ここまでで、どのように文章群が、インデックスの中に蓄えられ、それを検索しやすくする仕組みを構築するかは理解頂けたかと思います。
さて、以降では、それを使用して、ユーザが検索クエリを投げてから、どのように、目的のドキュメントが返却されるかまでの詳細について説明して参ります。
まずは、以下の図をごらん下さい。
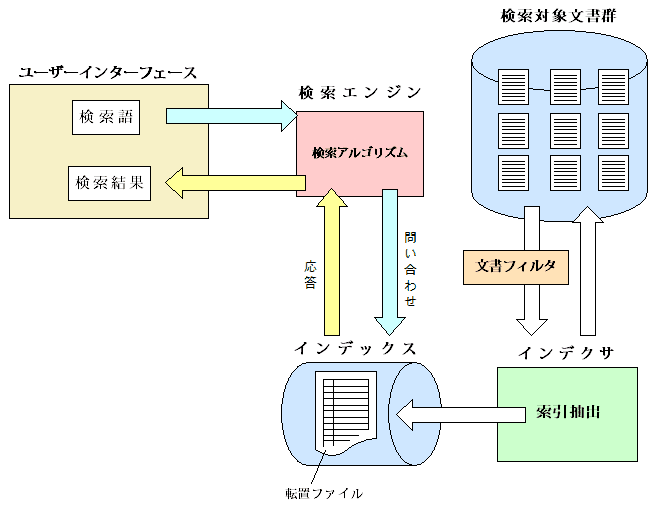
引用: https://ja.wikipedia.org/wiki/%E5%85%A8%E6%96%87%E6%A4%9C%E7%B4%A2
左側のユーザインタフェース部分が、ユーザのクエリの入力が来る部分です。
右側の検索対象文章群がクロール対象のWeb上のドキュメント群、下側のインデックス部分が、実際にドキュメントがインデックスされ、転置ファイル等が置かれている部分に相当します。
- 左側の、ユーザが検索クエリを入力してから、検索結果を受け取るまでの部分を、クエリのパイプライン
- 右側の、検索対象文章群をインデックスするまでの部分を、インデックスのパイプライン
と言います。
2の挙動に関しては、インデックスに関する説明部分で、既に詳しく解説をしましたので、1のクエリのパイプラインの挙動について、詳しく解説して参ります。
ユーザの問い合わせ(クエリ)
Google等の検索エンジンでは、ユーザが、検索ボックスにクエリを入力して、検索ボタンを押下すると、Web検索が開始されます。
この時に、ユーザのクエリは、インデッキシングの際の処理と同様に文字列抽出が行われている必要があります。
表1のように、転置ファイルが生成されている時に、文字列抽出の方法として、形態素解析が使用されていて、ユーザが「検索アルゴリズム」という語をクエリした場合、「検索|アルゴリズム」のように分かち書きが行われ、文章ID 1,2,3,5,6,8の文章が返却されます。
「検索アルゴリズム」のようなクエリの場合は、「検索」に関連するドキュメントも、「アルゴリズム」に関連するドキュメントも、どっちもユーザの関心が高いドキュメントになる確率は高そうです。
しかし、例えば「情報」という単語が含まれているドキュメントの中には、「生活に関するお得な情報」等、関係ないドキュメントが含まれている可能性が多々あります。
同様に、「アルゴリズム」に関しても、「画像認識のアルゴリズム」のように、検索アルゴリズムとは関係の無いドキュメントが多く含まれている可能性もあります。
これらを調整し、ユーザにとって必要なドキュメントを優先的に返すにはどうすれば良いでしょうか?
5.ランキング・アルゴリズム
SEO対策等をされた事がある方であれば、おそらく、「ページランク」や、「ランキングアルゴリズム」等の言葉は馴染みが深いと思います。
これらはまさに、上述のユーザにとって価値の高いドキュメントを上位に返すというためのアルゴリズムであり、この精度が高ければ高い程、ユーザにとって価値のある検索エンジンという事になります。
ランキングアルゴリズムの基礎を簡単に紹介すると、先ほどの「検索アルゴリズム」というユーザのクエリに対するランキングの例では、「検索」と「アルゴリズム」という単語のどちらかにヒットしたドキュメントよりも、その両者にヒットするドキュメントの方が、「検索アルゴリズム」についてのドキュメントである可能性が高くなります。
それを上位に表示させると、ユーザの期待に合致する検索結果になると言えるでしょう。
(表1のケースでは文章ID=2のドキュメントがそれに当たります。)
この転置ファイル上の単語と、ユーザのクエリの間の単語の一致率を、一致率スコアと定義し、このスコアが高ければ高い方が、一般的にはユーザの関心の強いドキュメントという事ができます。
これが最もベーシックなランキングアルゴリズムの考え方です。
その他にもランキングアルゴリズムには様々な工夫が施されています。
例えば、そのページが検索エンジンのユーザにクリックされた回数、そのページを閲覧したユーザの滞在時間(一般的に時間が長い方が、良いコンテンツと判断できる)等、様々なファクターを考慮して、ユーザにとって良質なドキュメントを返却する様々な工夫がなされています。