1. 自然言語とは何か?
言語は、私たちの生活の中に常にあり、また、なくてはならないものです。
そんな日々当たり前に使われる言語を見つめ直し、解析すると、どんな興味深いものが見えてくるのでしょうか。
1-1. 言語の世界とは?
「自然言語処理」の「自然言語」とは何か?
言語には、大きく分けて2種類あり、「コンピュータ言語」と「自然言語」に分けられます。
つまり、「自然言語」とは普段、私たちが日常で会話する言語のことで、「コンピュータ」のための言語と対比した言い方だと言えます。
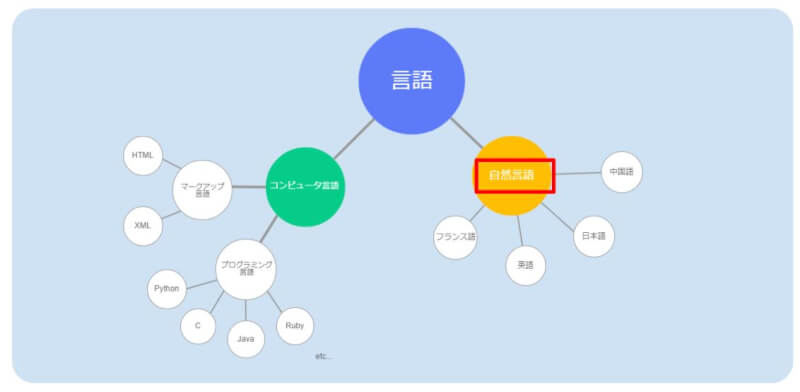
1-2. コンピュータ言語と自然言語処理の違い
一言でいえば、「解釈が一意であるかどうか」です。
自然言語では、聞き手によって受け取る意味が変わり、日常生活で誤解を生むことは、よく見受けられるかと思います。
これは日本語であろうと、外国語であろうと同じです。
対して、コンピュータ言語は、解釈がたった1通りしか存在しないものなので、「別の解釈」をしてしまったという誤解は絶対に起ききない仕組みになっています。
1-2-1. コンピュータ言語の例
1 * 2 + 3 * 4
1-2-2. 自然言語の具体例
警察は自転車で逃げる泥棒を追いかけた
- 解釈1: 警察は「自転車で逃げる泥棒」を追いかけた(泥棒が自転車で逃げる)
- 解釈2: 警察は自転車で、「逃げる泥棒」を追いかけた(警察が自転車で追いかける)
1-3. 蓄積される言語データの飛躍的増大
インターネットなど様々な技術の発達によって、何ヶ月もかけて手紙でしか伝えられない言葉がメールで一瞬にして伝えられるといったように、現代で交わされる言語の数は莫大に増加しています。

1-4. 言語(自然言語)があるからこそ人類は発展した
「共通の言語があってはじめて、共同体の成員は情報を交換し、協力し合って膨大な力を発揮することができる。だからこそ、”ホモサピエンス”は大きな変化を地球という星にもたらせたのだ」 言語学者、スティーブン・ピンカー(ハーバード大学教授)

1-5. つまり… その言語を解析する=可能性が無限大?
人類の進化の所以とも言われ、また技術発展によって増え続ける「自然言語」を解析することは、今まで暗闇に隠れていたものを明らかにし、更なる技術進化の可能性を秘めています。
またその「自然言語処理」の分析結果の精度は日々向上し、株式投資の予測やマーケティングでの利用など様々な分野で応用され非常に関心を集めています。
まずは、日常で使用されている自然言語処理にフォーカスを当てて、その先の可能性まで見ていきましょう。
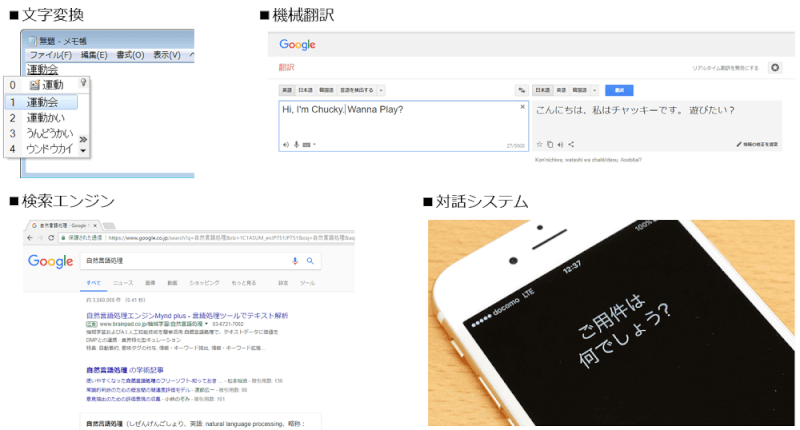
2. 身近な自然言語処理(NLP)
「自然言語を処理する」ということ一体どういうことなのでしょうか?
日々の生活でも取り入れられて、知らない間に私たちの生活を便利にしてくれている自然言語処理(NLP)について以下をはじめ様々なものがあります。
- 日本語入力の際のかな文字変換
- 機械翻訳
- 対話システム
- 検索エンジン
等々
3. 自然言語処理の流れ
以上のような技術を実現するのが自然言語処理で、まずは処理するための「前処理」というものを見ていきます。
はじめに、解析するための「元のデータ」が必要になり、このときできるだけ多くの高品質なデータを収集すると、後の処理が楽になるとともに、最終的に出来上がるモデルの品質が高くなります。
データの収集を終えたら、必要な部分を取り出したり不要なデータを削除したりします。
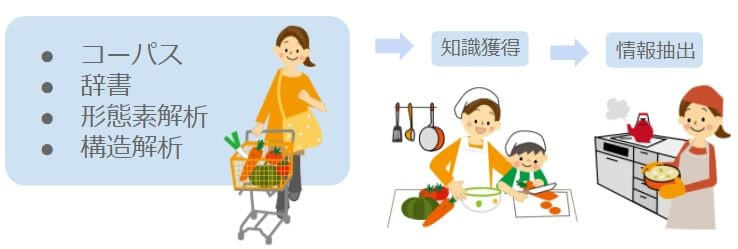
3-1. 自然言語処理のための前処理
3-1-1. コーパス
近年、コンピュータの記憶容量や処理能力が向上し、ネットワークを介してデータを交換・収集することが容易になりました。
その為、実際の録音やテキストなどを収集し、そのデータを解析することによって、言語がどのように使われているかを調べたり、そこから知識を抽出したりといったことが広く行われています。
このように、言語の使用方法を記録・蓄積した文書集合(自然言語処理の分野ではコーパスと呼ぶ)が必要になります。
3-1-2. 辞書
日本語テキストを単語に分割し、ある日本語に対する「表層形」「原形」「品詞」「読み」などを付与するなど何らかの目的を持って集められた、コンピュータ処理が可能なように電子的に情報が構造化された語句のリストである辞書も必要です。
3-1-3. 形態素解析
テキストを言語を構成する最小単位である単語を切り出す技術(形態素解析)も必要になります。
単語は言語を構成する最小単位で、文書や文を1単位として扱うよりも正確に内容を捉えられ、文字を1単位として扱うよりも意味のある情報を得られるというメリットがあるため、自然言語処理では、多くの場合、単語を1つの単位として扱っています。
英語テキストを扱う場合、基本的に単語と単語の間はスペースで区切られているため、簡単なプログラムでスペースを検出するだけで文を単語に分割できるのですが、日本語テキストでは通常、単語と単語の間にスペースを挿入しないため、文を単語に分割する処理が容易ではありません。
つまり、形態素解析は、日本語の自然言語処理の最初のステップとして不可欠であり、与えられたテキストを単語に分割する前処理として非常に重要な役割を果たしています。
3-1-4. 構造解析
コンピュータで文の構造を扱うための技術(構造解析)も必要です。
文の解釈には様々な曖昧性が伴い、先程の形態素解析が担当する単語の境界や品詞がわからないことの曖昧性の他にも、しばしば別の曖昧性があります。
例えば、「白い表紙の新しい本」
この文には、以下のような三つの解釈が考えられます。
- 新しい本があって、その本の表紙が白い
- 白い本があって、その本の表紙が新しい
- 本があって、その本の表紙が新しくて白い
この解釈が曖昧なのは、文中に現れる単語の関係、つまり文の構造の曖昧性に起因します。
もし、文の構造をコンピュータが正しく解析できれば、著者の意図をつかみ、正確な処理が可能になるはずです。
文の構造を正しく解析することは、より正確な解析をする上で非常に重要です。
3-2. 知識獲得
次に、以上で得た言語資源からコンピュータにとって有益な知識へ変換 をすることも必要です。
言語とは知識を表現する手段であり、近年、膨大な知識がウェブ上に自然言語で書かれるようになりました。
ただし、こうして言語で表現された知識は、そのままの状態では、コンピュータにとって単なる文字列に過ぎないのです。
これらの文字列を処理することによって初めて、コンピュータにとって有益な知識の状態にすることが可能になります(知識獲得)。
知識獲得を行う上で、
- 辞書に格納されているような語彙の知識
- その語彙と語彙の関係
が非常に重要な役割を果たします。
「胎児の発育にはタンパク質が不可欠である」と「肉類・魚類には蛋白質が豊富に含まれる」という2つの文を読めば、人間であれば「妊娠時の女性が肉類・魚類を摂取することは胎児の発育上、重要である」ということが推測できます。
しかし、こうした推測には、「蛋白質とタンパク質が表記が違うだけで同じ意味の語である(異表記)」かつ「胎児は母親の胎内において発育する(部分全体関係)」という知識が最低限必要になります。
また、こうした知識を獲得した上で、「胎児の発育に必要不可欠な栄養素は何か」という質問に対してコンピュータが回答するには、「タンパク質が栄養素の一種である(上位下位関係)」という知識を既に獲得している必要があり、「1.語彙の知識」だけでは不十分で想像以上に厄介です。
3-3. 情報抽出
最後に、自然言語から構造化された情報を抽出します(情報抽出)。
例えば、ある企業の社員情報を記録したデータベースに、社員番号、氏名、部署名、電子メールアドレスなどをフィールドや属性として持つレコードが格納されているとき、構造化されたデータは、コンピュータでそのまま処理できます。
4. 自然言語処理の8つの課題と解決策とは?
ここからは上記の自然言語処理の流れにおいて使われている具体的な手法と、そこに何の課題があってどのような研究が進行中であるかを簡単に紹介します。
4-1. 固有表現抽出
「モノ」を認識する
日付・時間・金額表現などの固有表現を抽出する処理です。
例)「太郎は5月18日の朝9時に花子に会いに行った。」
- あらかじめ固有表現の「辞書」を用意しておく
- 文中の単語をコンピュータがその辞書と照合する
- 文中のどの部分がどのような固有表現かをHTMLのようにタグ付けする
<PERSON>太郎</PERSON>は<DATE>5月18日</DATE>の<TIME>朝9時</TIME>に<PERSON>花子</PERSON>に会いに行った。
- 人名:太郎、花子
- 日付:5月18日
- 時間:朝9時
抽出された固有表現だけを見ると「5月18日の朝9時に、太郎と花子に関係する何かが起きた」と推測できます。
ただし、例えば「宮崎」という表現は、地名にも人名にもなり得るので、単に文中に現れた「宮崎」だけを見ても、それが地名なのか人名なのかを判断することはできません。
また新語などが常に現れ続けるので、常に辞書をメンテナンスする必要があり、辞書の保守性が課題となっています。
しかし、近年では、機械学習の枠組みを使って「後続の単語が『さん』であれば、前の単語は『人名』である」といった関係性を自動的に獲得しています。
複数の形態素にまたがる複雑な固有表現の認識も可能となっており、ここから多くの関係性を取得し利用する技術が研究されています。
4-2. 述語項構造解析
「コト」を認識する
名詞と述語の関係を解析する(同じ述語であっても使われ方によって意味は全く異なるため)
例)私が彼を病院に連れていく
「私が」「彼を」「病院に」「連れて行く」の4つの文節に分け、前の3つの文節が「連れて行く」に係っている。
また、「連れて行く」という出来事に対して前の3つの文節が情報を付け足すという構造になっている。
- 「私」+「が」→ 主体:私
- 「彼」+「を」→ 対象:彼
- 「病院」+「に」→ 場所:病院
日本語では助詞「が」「に」「を」によって名詞の持つ役割を表すことが多く、「連れて行く」という動作に対して「動作主は何か」「その対象は何か」「場所は」といった述語に対する項の意味的な関係を各動詞に対して付与する研究が進められています。
4-3. 語義曖昧性解消
書き手の気持ちを明らかにする
自然言語では、実際に表現された単語とその意味が1対多の場合が数多くあります。
「同じ言葉で複数の意味を表現できる」、「比喩や言い換えなど、豊富な言語表現が可能になる」といった利点はあるものの、コンピュータで自動処理する際は非常に厄介です。
見た目は同じ単語だが、意味や読みは異なる単語の例
金:きん、金属の一種・gold / かね、貨幣・money
4-3-1. ルールに基づく方法
述語項構造解析などによって他の単語との関連によって、意味を絞り込む方法。
4-3-2. 統計的な方法
手がかりとなる単語とその単語から推測される意味との結びつきは、単語の意味がすでに人手によって付与された文章データから機械学習によって自動的に獲得する方法。
ただ、このような正解データを作成するのは時間・労力がかかるため、いかにして少ない正解データと大規模な生のテキストデータから学習するか、という手法の研究が進められています。
4-4. 感情推定・評判分析
モノに対する人の評判や感情などの生の声を拾う
SNSやレビューサイトなど、インターネット上のメディアが普及するにつれ、企業のマーケティング活動などにおいて、モノに対する人の評判や感情などのナマの声が拾えるといったコンテンツの分析の必要性が高まっています。
人の評判や感情分析では基本的に、コンテンツを肯定的・否定的の2つに分類します。
- 単語ごとに肯定的か否定的かが示された辞書を用意
- 文章中に現れる表現ごとに評判を判断する
- おいしい → 肯定的な表現
- まずい → 否定的な表現
ただ、こうした単語の分類するための辞書を作るのは非常に手間がかかるため、各文書に肯定的と否定的のラベルを付けた正解データをあらかじめ作り、機械学習で解析します。
また複数の分類を組み合わせることで、肯定的・否定的に中性を加えた3つの分類や、5つ星評価などの段階評価も可能となります。
「食事はおいしいが、価格が高く、サービスの質も悪い」といった評価も可能になります。
ただし、
「小さい」:
- ホテルの部屋の場合、否定的な表現
- 携帯電話の場合、肯定的な表現
のように対象によって表現の意味が異なる場合もあり注意が必要です。
また、「食事がまずいわけではないが…」という表現があったときに「まずい」という表現を反転する必要があり、その「まずい」という否定表現と他との関係を解析する必要もります。
このように「単語を肯定的か否定的かに分類するための辞書をいかに構築するか」の研究が行われています。
またこうした細かな感情の種類については古くから議論があり、また文中の顔文字や絵文字なども感情表現において重要な役割を果たすため、その研究も行われています。
なお、感情推定、評判分析については、ブログにおける商品への言及からその商品の売上を予測する、Twitter上の人々の総合的な感情から株価を予測するなど実用的かつ理論的にも非常に井興味深い試みがなされています。
4-5. 照応省略解析
指示代名詞「こそあど言葉」や省略された語句を読み取る
自然言語の文章には、「文章中に現れる他のことがら」を指し示す(「照応」と呼ばれる)単語や表現が数多くあります。
いわゆる「ここ」「そこ」「あれ」といった日本語における指示代名詞「こそあど言葉」や英語の「it」「this」といったものです。
指定代名詞以外の照応
- 代名詞:「太郎くんは学生です。彼の専攻はコンピュータ科学です。」
- 省略:「太郎君は講義を受けています。しかし、しばらくすると眠ってしまいました。」
- 外界:「ちょっとそこの人、起きて下さい」
- 単語間の関係:「そこに怒っている人がいました。もちろん太郎君の先生です。」
様々な照応現象のうち、日本語の文章で顕著に見られるのは「省略」です。
例えば2つめの文では「眠ってしまった」動作の主体である「太郎くん」は省略されています。
日本語の場合、助詞「は」から文章のトピックを特定できる事が多く、また、様々な知識・ルールを駆使して照応関係を解析することはできますが、言語現象とは複雑なので、知識・ルールを人手で全てを網羅するのは非常に大変です。
そのため、近年の研究では、ある文章データベース(コーパス)を用意し、その文章中の照応関係にあらかじめ正解を振っておき、その情報から、機械学習の技術を用いて照応を解析するモデルを自動的に学習する手法といった、コーパスからの解析モデルの学習へと焦点が移ってきています。
4-6. DRS(談話表示構造)
文と文とのつながりを調べる
単語や文の解析など、単一の文や周囲の1~2文の関係のみに注目してきましたが、自然言語では、単一の文だけで成り立つわけではありません。
4-6-1. 人と人との会話(対話)
会話に参加する人が直前の発話に対して意見を述べたり、反論したりしながら、徐々にトピックを変え話を進行させます。

4-6-2. 演説や講演など(独話)
人が単独で話す場合にも、前に発話した内容を受けて、補足、例示、話題転換などを行いながら、話を展開していきます。

このように、自然言語では、何らかの関係のある一連の文(発話)の関係を捉えることが重要です。
このような一連の文は談話と呼ばれ、談話自体を生成する技術のほか、文のまとまり、文章の構造、意味などを解析する技術などがげ研究されています。
近年のスマートフォンの普及に伴って、アップルの「Siri」やNTTドコモの「しゃべってコンシェル」など、音声対話を通じて情報を検索したりする対話システムも普及しつつあります。
情報検索システムとのインターフェース役を果たすのが一般的で、ユーザーの発話を理解・解釈しながら、「現在の状態に従って返答をする」「データベースを検索する」といった適切なアクションを起こします。
ほぼこれらのシステムでは、使われる状況が想定されているので、文法や語彙があらかじめある程度制限されているのケースがほとんどです。
つまり、システムの想定していない発話が入力された場合などに適切な対応ができません。
一般に、どのような状況でもどのような発話に対しても対応のできる汎用のチャットシステムを作ることは、ほぼ人間の知能を模倣することに近く、人工知能の永遠のテーマという風に考えられています。
4-7. 含有関係認識
質問応答や情報抽出、複数文書要約を実現する
- スティーブ・ジョブズはアメリカでアップルという会社を作った。
- アップルはアメリカの会社だ。
このように、1だけ読めば、2を推論できる状態を「1は2を含意する」という。
2つのテキストが与えられたときに、片方がもう片方を含意するかどうか認識するタスクは含意関係人認識と呼ばれ、質問応答や情報抽出、複数文書要約など様々な用途に応用されています。
例えば、質問応答システムでは、「アップルのはどこの会社ですか?」という質問があった場合に、1の記述しかなくても、2を推論できるため、そこから「アメリカ」という回答が得られます。
2つのテキストに共通する単語がどのくらい含まれているかを見るだけで、そこそこの精度で含意関係の判定ができますが、数値表現、否定、離しての感じ方などを含む文の意味解析は一般的に難易度が高く課題となっています。
4-8. その他
「意味」の問題
「ちょっとこの部屋暑いね」という発話は、単にこの部屋が暑いという事実を表明している文であるとシステムは解析しますが、人間であれば、この発話を聞いて、「発話主が不快である」「部屋の窓を開けると涼しくなる」「冷房をつければ涼しくなる」といった推論を経て、「エアコンでも付けようか」と提案するなど、いわゆる人間味のある行動を取ることができます。
これには、「夏には窓を開けたり、冷房をつけると涼しくなる」という常識など、発話以外に大量の知識および推論が必要となってきます。
これらの知識や常識をコンピュータでどのように表現・処理するかは、自然言語処理のみならず人工知能の分野における長年の問題の1つです。