1. あらすじ
昨今の人工知能ブームで、Siriに話しかけている人や、店頭にいるpepper等のロボットに話しかけている人、また、Line上でりんなに話しかけて対話を楽しんでいる人等が増えてきていると思います。
また、商業的な観点からは、コンタクトセンタ等の問い合わせ対応の手間を軽減させるために、チャットボットを導入して、今までは人間のオペレータが問い合わせ対応をしていた部分を(一部でも)代行させるという流れがだんだんと主流になってきています。
とにかく、世間では、人工知能と対話をしたい、という要望が強くなってきており、いつか人間と同等に人工知能と対話ができるように、様々な分野で対話システムに関する研究が行われてきています。
読者の方も、何らかの形で、人工知能と対話をした事がある方、siri等の対話アシスタント等を日常で使用している方等、いらっしゃるかと思いますが、正直、対話がスムーズに行えるかというと、まだ理想には遠い状態かと思います。
しかしながら、用途を絞り込む事で、十分に実用的に活用する事は出来ます。
また、人工知能の花形分野である、NLP(自然言語処理)を活用し、人間の思考等を理解させて対話システムを構築することは、今後の期待が最も大きい分野の一つと言えるかもしれません。
今回は、そんな発展途上ではありますが、将来が期待できる対話システムに関して、その簡単な歴史から、その仕組み、最新のトレンドまで、詳しく解説していきます。
2. 対話システムの歴史
2-1. ELIZA
世の中で、一番最初に開発された対話システムは、ELIZA(エリザではなくイライザ)と呼ばれており、1960年代までその歴史を遡る事になります。
この頃は、人工知能という言葉が世の中に徐々に浸透し始めた、いわゆる「黄金時代」とされた時期で、今の人工知能技術を支える基盤となる、様々なアルゴリズムが劇的なスピードで研究開発され、人工知能が人間を超える日も近いと世間が躍起していた時期でした。
その中で、MITのジョセフ・ワイゼンバウムが1960年代にイライザを書き始めたのですが、イライザは完全に、スクリプト型(パターンマッチング型)の動作をするように設計されいました。
毎回決まった入力を仮定して、それに対して決まった応対をするため、真の意味で人工知能的な思考を実現していない事から、人工無能という言葉が世の中に誕生する事になり、その人工無能の代表格となりました。

当時のマシンスペックを考えれば、イライザがスクリプト型である事は何の疑いもなく、また音声認識等のインタフェースは備えず、今にして見れば非常にシンプルな作りでした。
それでも、人間が、機械と対話をするという試みは画期的であり、イライザは後の全ての対話システムの土台となりました。
また、1950年代にアラン・チューリングによって発案された、機械が知的かどうかを判定するテストである、チューリング・テストの活動も活発化しだし、現在もチューリング・テストは継続されています。
2-2. 人工無能ブーム
イライザで幕を開けた、人工無能ブームは様々な方向に飛び火し、ゲームの世界や、チャットの世界において、だんたんとイライザ型の人工無能が普及し始めてきました。
日本では、「ゆいぼっと」「ししゃも」「人工無能うずら」等と呼ばれる人工無能ボットが生み出され、一部の愛好家の間で、日本語に対応した人工知能が生み出されてきました。
2-3. エキスパートシステム
その後、人工知能は、当時のマシンパワーの非力さから来る、処理能力の限界や、理想と現実との間のギャップ等に苦しまされましたが、用途を狭める事で実用レベルになるのではないかという説が囁かれるようになり、その皮切りになったのが、エキスパートシステムです。
エキスパートシステムは、今までの対話システムとは発想を変えて、ある特定の分野にターゲットを絞り、特定の専門用語等を訪ねた時に、人間よりも的確に答える事ができる等、実用レベルで使用可能であったため、世間の大きな注目を集めました。
ただし、それでも当時のマシンパワーは非力で、最初は注目され始めていたエキスパートシステムも限界が見え出し、ここから対話システムは長い冬の時代に入り、世間からは忘れ去られた過去の存在となりました。
2-4. Siriの登場
さて、2000年代後半に、長い冬の時代をディープラーニング等の機械学習技術の進歩が打ち破り、対話システムにも大きな進歩が訪れました。皆様もお馴染みのSiriの登場です。
Siriは、元々アメリカ国防高等研究計画局で、兵士を戦場でサポートするための人工知能プロジェクトとして開発が始まりまり、巨額の予算が投じられて研究がスタートしました。
後にApple社に売却される事になり、iPhoneでお馴染みのSiriが、ユーザの発言を意味解釈して、正しい回答を表示する、今までの人工無能の枠をこえた、高いレベルの意味解釈技術が大きな注目を集め、現在の対話システムの代表格となりました。
Siriを皮切りにこれまで眠っていた、対話システムへの興味が再び高まり、それが現在のチャットボットブームに繋がっていきました。
2-5. チャットボートブームの到来
さて、昨今、チャットボットという言葉が世間を賑わせていますが、チャットボットとは何かと言うと、チャットと、ボットを掛け合わせた言葉であり、テキストや、音声認識等の技術を用いて、人間と対話を実現させる為のものです。
コンタクトセンタの問い合わせ対応など、限定的ではありますが、実用レベルで使用されるチャットボットや、Line上で話題になっている、女子高生AIをイメージした「りんな」(マイクロソフトが開発)のように、雑談に対して反応するチャットボット等も増えてきています。
また、近年ではディープラーニングのブレークスルーもあって、チャットボットは非常に活発化しているある種のトレンドとも言えるでしょう。
3. 対話システムを構成する2つの仕組み
それでは本題に入っていきましょう。
おそらく読者の皆様は対話システムの仕組み自体に興味があるかと思いますが、現在の対話システムには大きく分けて、以下の2つの仕組みで構成されています。
- Retrieval model
- Generative model
それぞれ詳しく説明を進めて参ります。
3-1. Retrieval model
Retrieval modelとは、基本的にはルールベースで対話を構成する方法で、予め対話のシナリオ(スクリプト)を定義しておき、決まった質問に対して、決まった回答を返却する、先ほど説明をした人工無能モデルに近い動きをします。
下の図は、このRetrieval modelの動作を図示した一例です。(あくまで一例なので、全てのモデルがこの通り動いている訳でないのことをご了承ください。)
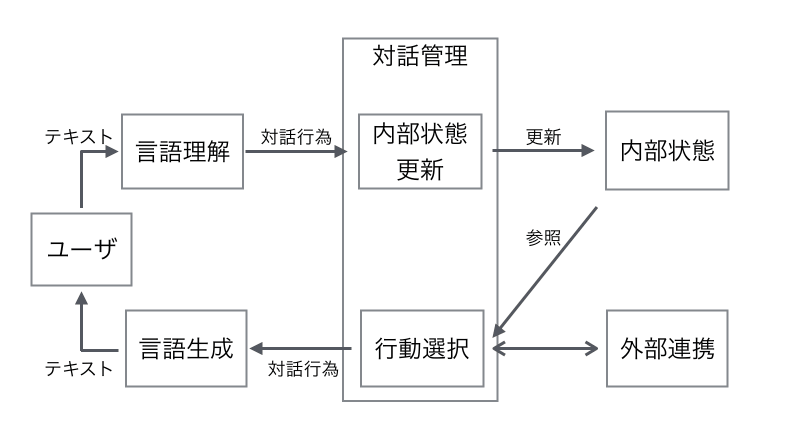
引用:http://qiita.com/Hironsan/items/6425787ccbee75dfae36
以下に、上記の図の流れを簡単に説明すると
3-1-1. ユーザからの入力は音声であれ、チャットであれ、テキストに変換されてシステムに入力
3-1-2. 対話システム内で、ユーザのクエリに対してその意味を解釈させる(言語理解)
この方法は、完全な文字列一致で判定を行う、単純な方法もあれば、類似文章検索等で、言葉のゆらぎや、表現の違いなどを吸収し、過去の対話スクリプトとどのくらい意味的な距離が近いかを計算して求める事もあります。
3-1-3. ユーザのクエリの言語理解がすんだ後に、対話システムは現在の対話の内容に基づいて、「内部状態」を更新
ユーザが同じ質問をしても、例えばそれが会社でする質問なのか、自宅でする質問なのかによっても、期待する回答は変わると思うので、そういったユーザの外的な環境情報等を考慮して、対話システムの内部状態を更新します。
また、対話システムによっては、こういった内部状態を保持せず、完全に一問一答形式で回答を生成するだけのものもあります。
3-1-4. 対話システムの内部状態が決定された後は、ユーザに対するレスポンスの選択(行動選択)
ここでは、ユーザの質問によっては、対話システムは何も応答しない選択をする時もありますし、ユーザが不適切な発言をした場合は、それを抑制する文章を回答として生成したりします。
その時の対話システムの内部状態と、ユーザの発言から、もっとも適切な反応を取捨選択します。
3-1-5. 対話システムが行動選択した後は、状況に応じて外部連携のAPI等を呼び出す
どのような場合に外部連携が必要になってくるかというと、「今日の天気を教えて?」等、日時によって答えが変わるような情報に関しては、通常、対話システムは内部にそのデータを用意していないため、外部のAPI等に問い合わせて、その情報を使用して、回答を生成する事になります。
3-1-6. 対話システムがユーザに返答する回答を生成したら、それをユーザに返答(対話行為)
通常、回答はテキストで生成されますが、ロボット等の機械を使用する場合は、音声合成技術などを使って、それを読み上げより親近感を高める等の工夫がなされています。
勿論、予め断っておいた通り、これが全ての対話システムのアーキテクチャでは無いですが、Retrieval modelベースの対話システムは、一般的にこういった構造を利用しているかと思います。
3-2. Generative model
こちらは、先ほど紹介したRetrieval modelとは違って、基本的に予め用意したスクリプト等は利用せずに、スクラッチから回答を自動生成するアプローチです。
文章の自動生成技術に関しては、昔から様々な研究が幅広くなされており、手軽な方法としては、マルコフ過程を利用した、マルコフ連鎖により、ある単語から、次の単語への状態遷移を予測して、それらを繋ぎ合わせて文章にする方法等があります。
また、近年、めまぐるしい発展をあげているのは、ディープラーニングの一種である、再帰型ニューラルネットワーク(RNN)の一種である、LSTMを利用する方法です。
本記事では、LSTMについて詳しく説明する事は、趣旨から外れてしまうため、LSTMの説明については最小限にとどめますが、非常に簡潔に説明をすると、ある単語が入力された際に、その次の単語を、過去に入力された単語を考慮しながら出力できるという、マルコフ連鎖の上位互換で、近年、文章生成技術として、非常に大きな注目を集めている技術です。
LSTMが凄いのは、学習には大量のデータが必要になりますが、うまく学習させると、その学習させたトレーニングセットの癖をよくとらえた文章を生成するようになります。
そういった性質を利用して、人工知能に夏目漱石のような小説を書かせる試みをしたり、何かのアニメのキャラクターのように発言させるボットを作ったりと、近年色々な試みが試されています。
Generative modelでは、このLSTMをベースとして作成されているのもが多く、先ほど説明したように、アニメのキャラクターのような発言を繰り返すボット等の作成に使われています。
しかし、LSTMの問題は、生成される文章が、文章として意味の通らないものが生成される事が多く、ユーザの意図を理解しない一方通行の対話システム(暇つぶしの雑談システム)等には良いのですが、ある目的に特化させたチャットボット等を作り込む際には、ユーザの質問を正しく理解させて、意味のある回答を生成する必要があるため、Generative modelのハードルは非常に上がります。
Generative modelで、こういった質問応対システムを作成する場合は、一般的には機械翻訳と同じテクニックが用いられ、同じくLSTMを駆使しながら、ユーザの質問を、抽象的な概念に変換し、それに基づいて、回答を予測する、というような非常に難易度の高い回答生成方法を採用しています。
Generative modelは、このように非常にハードルは高いものの、次世代の人工知能技術として大きな注目が集まっているため、現在、国内外の色々な研究機関が総力をあげて、研究開発に取り組んでいます。
LSTMの実践例に関しては、文章生成AI(LSTM)に架空の歴史を書かせた方法とその結果 をご覧下さい。
4. オープン・ドメイン vs クローズド・ドメイン
さて、対話システムについての解説をした際に、雑談向けの対話システムの話や、ある用途に特化した対話システムの話などをしてきましたが、前者のような雑談システムなどでは、対象にする範囲が特定の定義も何も無く雑談全般という事で非常に幅が広いため、open domainという呼ばれ方をします。
対して、後者のように、例えば、航空会社のFAQ対応向けにチャットボットを実装するなど、適用分野と用途を絞り込んで対話システムを作る際に、その絞り込んだ専門分野や、ある特定の領域の事を、分野が限られているという意味で、Closed domainと呼びます。
想像するのは難しく無いかとは思いますが、一般的に、open domainは、ユーザのクエリ(問い)が想定でき無いため、難易度は非常に高くなり、またclosed domainは、分野にもよりますが、ユーザの質問は限定的で、予測と対策が立てやすいため、難易度はopen domainよりも低くなる傾向があります。
勿論、どういった対話を目的にするかにもよります。
下の図は先ほど説明した、Retrieval mode、及びGenerative modeを、open domain、及びclosed domainに適用した場合の難易度を表しています。
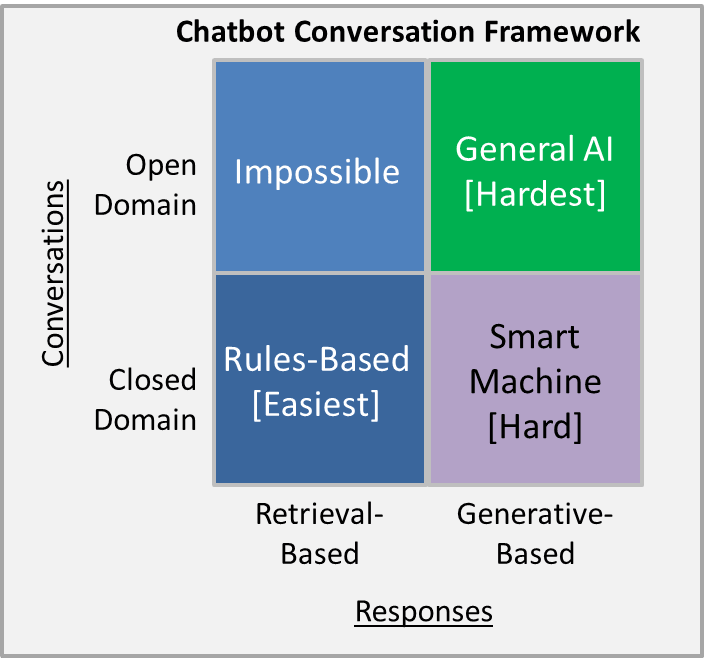
引用:https://chatbotslife.com/ultimate-guide-to-leveraging-nlp-machine-learning-for-you-chatbot-531ff2dd870c
非常に直感的な結果かと思いますが、ある特定の専門領域、目的に特化しているclosed domainには、Retrieval modeでの対話システムを構築する事が、難易度的に最も簡単になり、実装が比較的容易で、カスタマイズもしやすいので、要求されるシナリオに合わせて、対話システムを作り込んで、そのパフォーマンスを向上させる事ができます。
ただし、一般的にopen domainはRetrieval modeでは一般的に対処できないとされていて、理由としては雑談のようにとりとめもない領域では、ユーザのクエリの内容は無限大で、それをきっちりと定義する事は事実上不可能であり、事前にスクリプトを用意するような対処方法が、通用しないと言っても過言で無いからです。
それでは、一方Generative modeの方を見ていくと、前述の通り、一般的に意味の通った対話システムを実装する難易度はGenerative modeの方が、Retrieval modeよりも高く、closed domainであっても、ユーザのクエリに対して、意味の通った回答を生成する事は難しく、また、膨大なトレーニングデータを要します。
それでも、closed domainにGenerative modeをうまく適用できた場合、返答がRetrieval modeのように、常に同じ回答文ではなく、時と場合に応じて、言い回しが微妙に変化したり、より知性を感じさせる対話システムに仕上がります。
そのため、Generative modeを用いた、または、一部Retrieval modeの中に、Generative modeを織り交ぜた対話システムの研究開発が盛んになってきています。
また、open domainに対しては、Retrieval modeではもはや対処不可能という事は説明しましたが、Generative modeでの対処も、そもそもopen domainのトレーニングセットを効率よく収集する方法も無いため、困難を極めます。
ここはまさに、人工知能という言葉が世の中に最初に登場した時から、誰もが夢見続けた、機械とあらゆる対話を思いのままにするという事になるので、現在の人工知能の限界をもう一歩推し進めようと、様々な研究機関がこの分野に対する研究開発に取り組んでいます。
また、open domainのトレーニングデータを収集する動きも盛んになっていて、被験者に日常会話のデータ収集を依頼する等の長期的な取り組みもなされています。
5. 最新の対話システムの動向とは?
さて、今までテキストベースでの対話システムについて解説をして参りました。
確かに、テキストの意味を理解して、それに合致した返答を回答する事は、非常に重要ですが、人間は実際に誰かと対話を行う時には、本当に対話の内容そのものだけを意識しているでしょうか?
そうであれば、実際の対面での会話も、Line等の電話アプリを使用した会話も、全く同じ結果になると思いますが、実際は、電話での対話は、対面での会話に比べてやりにくいと思った方が多いと思います。
同様に、チャットアプリでのテキストだけの対話よりも、電話での対話の方がやりやすいと感じる方も多いかと思いますが、この違いは何でしょうか?
ある調査研究では、人間がある発話からその言葉の意味を理解するには、言葉7%、声38%、表情55%の割合で重視するという結果があります(A.Meharabian 1968)。
つまり、テキストだけではなく、相手の声のトーンを聞き、相手の顔の表情まで見なければ、本当の意味で対話は成立しないので、これはテキストベースでは到底達成でき無い事なのです。
例えば、「おい」という言葉を相手が発した時、それが相手が怒った顔つきで、激しい口調で「おい」といった場合は、そこには怒りの感情が込められていると判断できるでしょうし、逆に、相手が、にこやかに、明るいトーンで「おい」と発言した場合は、それはつっこみのようなニュアンスでジョークをいっているような状況で、楽しい感情がこめられていると解釈できます。
つまり、テキストだけでは相手の感情まで判断する事は不可能なので、そういった意味では、真の対話システムの実現は達成できません。
ですので、最先端の対話システムの研究では、テキストのみから対話を実現させるのでなく、顔の表情や、声のトーン等から感情推定を行って、それを対話システムの回答に応用する研究開発が盛んになってきています。
こちらについての詳細を記述すると、とても長くなってしまうので、それはまた別の機会で詳しく説明をしようと思いますが、今の最先端の研究領域では、このマルチモーダルな視点から対話システムの限界を突破しようとする動きがあります。
まだ、ブレークスルーと呼べるものは対話システムには起こっていませんが、ぜひその限界を突破していきたいと考えています。