※サンプル・コード掲載
1. あらすじ
人工知能という言葉が、昨今、ますます身近になってきており、Siriなどの対話システムも日々発達してきています。
また、人間の言語を人工知能に解釈させる対話システムの需要が増えると共に、NLP(自然言語処理)のニーズも日に日に高くなって来ています。
NLP分野では、画像処理系や、音声処理系と比較すると、まだ技術的なブレークスルーが起こっているという状況では無く、他の分野に比べて人工知能関連の技術適用は、限定的と言えるかもしれません。
しかしながら、NLPの分野でも、当然、機械学習は使用されますし、ディープラーニングをNLP分野に使おうとする動きも多く見られています。
今回は、その中で対話システムの制御等に使われる、入力文章の意図、主に対話カテゴリーの分類を、NLP、及び、機械学習を用いて、なるべくシンプルな手法で実装してみます。
文章のカテゴリー分類とは、例えばブログを書いた時のカテゴリ、メール内容のトピック、チャット内容の感情の分類などに使えます。
これだけでも結構汎用的に様々な場面で使える気がしてきますね。
- 開発環境: Windows or Mac or Linux
- プログラミング言語: Python(3.X)
2. 人間はどのように文章・テキストを分類しているのか?
具体的なコードの実装に進む前に、まずは、人間はどのように対話中で、文章・テキストの意図(カテゴリー)を把握しているか考えてみましょう。
例えば、以下の文章を読んでください。
「今日は晴れかな?」
「明日の東京の天気はどうだろう?」
「現在の神奈川は雨が降っていますか」
・・・
人間の頭であれば、これらが「天気」についての質問であることは、すぐに理解できるかと思います。
では、以下はどうでしょうか?
「現在地から渋谷まで最速で行く方法は?」
「この先、渋滞しているところはありますか?」
「電車だと、東京駅から名古屋までどの位?」
「千葉駅付近の地図が見たい」
これらに関しては、人によって多少の捉え方の差は生まれるかもしれません。
人によっては「地図」についての話だと思う方もいるでしょうし、「乗り換え案内」と捉える方もいるかもしれません。
しかし、何かしら「ナビゲーション」に関連する意図の話である事は確かそうです。
それでは、これらの文章のカテゴリー把握は、人間はどのように行っているのでしょうか?
まず、天気の例ですが、文章を見直してみると
「今日は晴れかな?」
「明日の東京の天気はどうだろう?」
「現在の神奈川は雨が降っていますか」
・・・
上記のように、赤字で示した単語等から、人間の頭はこれらの文章が「天気」についての話題であるという事を抽象的に把握しているはずです。
それは、「晴れ」「天気」「雨」等が、天気を思わせる単語であり、そういった単語から連想しています。
それではナビゲーションの例ではどうでしょうか?
「現在地から渋谷まで最速で行く方法は?」
「この先、渋滞しているところはありますか?」
「電車だと、東京駅から名古屋までどの位?」
「千葉駅付近の地図が見たい」
上記に関しても、赤字の部分を見ていくと、
- 「渋谷」「東京駅」等、地名に関する固有名詞
- 「この先」「現在地」等、場所を連想する単語
- 「地図」等、ナビゲーションを連想しそうな単語
これらの周辺単語が文章の中に入っているため、上記の文章が、「天気」や「ナビゲーション」の事についてのものだと、人間の頭は漠然と把握をできる訳です。
おそらく、勘のいい読者の方であれば、ピンときたでしょうが、これらの作業を機械にさせる事ができれば、文章の意図の把握、つまり、文章のカテゴリー分類を機械化できるのです。
それでは、具体的な手法について考えていきましょう。
3. 形態素解析とは
「今日は晴れかな?」
「明日の東京の天気はどうだろう?」
「現在の神奈川は雨が降っていますか」
これらのクエリ(問い)から、「晴れ」「天気」「雨」「降って」等を抽出出来れば、これらの文章を「天気」のカテゴリーだと判定させるためのロジック実装への大きな足がかりになりそうです。
そのための最も簡単な方法はと言うと、「晴れ」「天気」「雨」・・・等、天気に関連しそうな単語を予め集めた辞書を事前に用意しておいて、その辞書に存在する単語が、文章中に存在するかどうかをチェックしていく事です。
(通常、こういった辞書をgazetteerガゼッティアといいます。)
しかしながら、長い文章や、gazetteerのサイズが巨大になってくると、計算量が非常に増加してしまう事もあるため、マシンパワーが少ない環境で作業している場合などは、何らかの工夫をする必要があります。
(勿論、この方法も十分に有効な方法で、gazetteerをしっかりと用意しておくことは、カテゴリ分類の精度を向上させる事に繋がる為、非常重要な作業となってきます。)
そこで、有効な手段として登場するのが、形態素解析という方法です。
形態素解析は、文章を最小の構成単位である単語(名詞、動詞等)に分かち書きを行う技術です。
形態素解析器に関しては、オープンソースで提供されており、MeCabという形態素解析器が一般的に有名です。
(MeCabのpythonでのセットアップ方法に関しては、MeCab(形態素解析)をPythonから2分で使えるようにする方法 をご参照下さい。)
形態素解析器を使用すると、入力した文章を分かち書きしてくれるため、分かち書きをした単語に対して、gazetteerの単語とマッチするかチェックすれば良い事になります。
以下に、形態素解析器としてMeCabを利用し、pythonでgazetteerの単語と照合チェックする実装例をお見せ致します。
import MeCab
text = '今日は晴れかな?'
#天気の関連語をまとめたgazetteer
weather_set = set(['晴れ','天気','雨'])
mecab = MeCab.Tagger("-Ochasen") #MeCabの取得
tokens = mecab.parse(text) #分かち書きを行う
token = tokens.split("\n")
#以下、分かち書き後の単語を抽出
for ele in token:
element = ele.split("\t")
if element[0] == "EOS":
break
# 単語の表層を取得
surface = element[0]
if surface in weather_set:
print(surface)
簡単にコードを説明すると、「MeCabオブジェクトをpythonから取得し、入力文章の分かち書きを行って、その単語の表層(surface)が、gazetteerに存在したら出力をする」という、非常にシンプルなコードとなっています。
形態素解析器の挙動の詳細を知りたい場合、上記コードの、elementをプリントアウトしてあげると、詳細が把握できるかと思います。
これで、gazetteer中の単語が、入力文章中に存在するかどうかを確認する方法については、ご理解頂けたかと思います。
それでは続いて、実際に簡単にカテゴリー分類をする方法について解説して参ります。
4. シンプルなテキスト分類の実装方法
機械学習を用いる前に、先ほど紹介したgazetteerを用いて、簡素ですが、非常にパワフルにカテゴリー分類する方法について、具体的に説明していきます。
ここで、入力文章は、「天気」と「ナビゲーション」の2つのカテゴリーのみと仮定して、そのうちのどちらかにカテゴリー分類するように実装してみます。
先ほどの内容から、カテゴリを分類する際には、そのカテゴリに対応したgazetteerが、事前に用意されている必要があります(今回は「天気」と「ナビゲーション」)。
まずは、このgazetteerを作成する方法から検討していく事としましょう。
4-1. Gazetteerの作成方法
結論からいうと、gazetteerの作成方法に関しては、何か正解がある訳ではありません。
ご自身で、思いつく単語を手作業で羅列していく方法も、外部のライターさん等に依頼して、関連語を羅列してもらう方法もあります。
ただ、マニュアルでgazetteerを作成していくと、どうしても人手によるミスなどが発生する可能性があります。
また、なるべくここに対して人手をかけないようにする事が、後々の作業の効率化を考えると重要になってきます。
そこで、よく活用する方法としては、web上から適切なリストを検索する方法です。
特に、「人名」や「地名」等の一覧は、Wikipediaをはじめとした、webサイトなどに整備されてまとめられている事が多く、そういったリソースを活用しながら関連するgazetteerを構築すると、効率よく進めることが出来ます。
また、文章を構造化し大規模に集積したものをコーパスと言います。
その様な方法で、gazetteerの網羅率をなるべく上げておく事が、分類精度の要となってきます。
4-2. テキスト分類の実装
それでは、実際にテキスト分類の簡易実装方法について解説して参ります。
ここでは、説明を簡単にするために、gazetteerの辞書には最小限のエントリのみを追加し、入力文章も単純な短文を仮定しています。
それでは、まずは具体的なコードの実装内容を見ていきましょう。
import MeCab
#天気の関連語をまとめたgazetteer
weather_set = set(['晴れ','天気','雨','曇り'])
#ナビゲーションの関連語をまとめたgazetteer
navi_set = set(['渋谷','東京','電車','地図'])
mecab = MeCab.Tagger("-Ochasen") #MeCabの取得
def classify_category(text):
tokens = mecab.parse(text) #分かち書きを行う
token = tokens.split("\n")
weather_score = 0 #天気である可能性のスコア
navi_score = 0 #ナビゲーションである可能性のスコア
#以下、分かち書き後の単語を抽出
for ele in token:
element = ele.split("\t")
if element[0] == "EOS":
break
# 単語の表層を取得
surface = element[0]
if surface in weather_set:
weather_score += 1
if surface in navi_set:
navi_score += 1
if weather_score > navi_score:
print("天気")
else:
print("ナビゲーション")
上記のコードで、classify_categoryというメソッドを実装していますが、こちらがカテゴリー判別をする関数で、ここに文章を入力すると、その文章が「天気」または、「ナビゲーション」のどちらのカテゴリーに属しているかを分別します。
ロジックとしては非常に単純で、まずは、「天気」「ナビゲーション」それぞれのgazetteerを用意し、入力された文章を、MeCabによって、分かち書きを行い、分かち書きされた単語が、それぞれのカテゴリーのgazetteerにどの位存在しているかをカウントしています。
最終的に、そのカウントスコアを比較して、スコアが高い方のカテゴリーを、判定カテゴリーとして表示します。
この方法は、非常にシンプルながらそれなりの精度で動くので、色々と試してみると良いでしょう。
ただし、この方法はあくまで簡易実装なので、gazetteerの辞書のエントリに結果が強く依存します。
例えば、ヒットした単語の中で、特に強調したい単語がある場合等のきめ細かい調整はできないため、分類精度的にはそこまで高くはならないというのが実情です。
そこで、以降は少し難しくなりますが、機械学習(MLP 、いわゆるディープラーニング)を用いた、カテゴリー分類の実装方法について、ご説明させて頂きます。
5. ディープラーニングを用いたテキスト分類の実装方法
今回は簡単な割に精度が高い、Bag of wordsとニューラルネットワークを組み合わせた手法でやってみたいと思います。
5-1. 実行環境
引き続き、python3を使用します。
以下のライブラリをインストールして下さい。
pip install numpy
pip install scikit-learn
pip install pandas
コーパスには livedoorニュースコーパス を使用します。
少し加工する必要があるので、下記の記事の【2.コーパスの準備】をお読み頂き、corpus.txtというファイルを作成して下さい。
scikit-learn(機械学習)の推定器:Estimatorの選び方
5-2. Bag of Wordsとは?
これはそのままの意味で、文章を単語単位に区切り、それをバッグに詰め込んでしまうイメージです。
つまり、文章をバラバラにしてしまいますので単語の順番は考慮しません。
順番情報を捨ててしまって大丈夫なの?と思いますよね。
もちろん情報を捨ててしまっていることになるのですが、自然言語処理界では広くこの手法が使われています。
それは、順番の情報を捨ててしまっても多くの場面で精度を出すことが可能であるからです。
英語の文章の場合、そのまま単語ごとに区切ってバッグに入れてしまう事が多いのですが、日本語の場合はそうはいきませんので、文章を何らかの単位で区切って分割する必要があります。
ここで多く使われるのが、前述の形態素解析という技術です。
形態素解析を行うと、「私は海が大好きです」という文章が、
「私/は/海/が/大好き/です」と切られます。
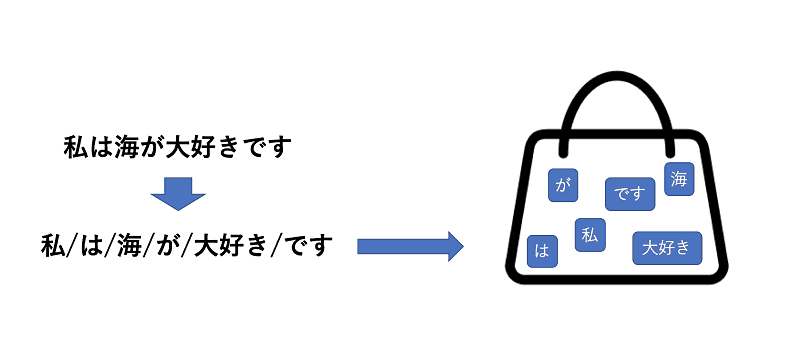
基本的にはこのように全てのテキストを形態素に分解していき、出現する全ての単語を把握したあと、全ての単語に対してテキスト中に出現するかどうかというベクトルを作成します。
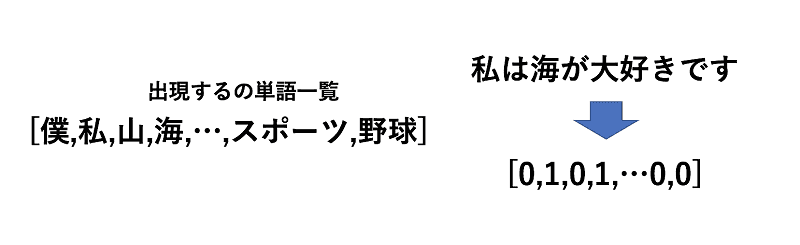
その後、ニューラルネットワークに対してこのベクトルを入力とし、出力をカテゴリとして学習を行います。
wikipediaより引用
5-3. テキスト分類の実装
下記のファイルをそれぞれ作成します。
また、modelsというディレクトリを作成しておきます。
nlp_tasks.py
# -*- coding: utf-8 -*-
#! /usr/bin/python
import MeCab
from sklearn.feature_extraction.text import CountVectorizer
def _split_to_words(text):
tagger = MeCab.Tagger('-O wakati')
try:
res = tagger.parse(text.strip())
except:
return []
return res
def get_vector_by_text_list(_items):
count_vect = CountVectorizer(analyzer=_split_to_words)
bow = count_vect.fit_transform(_items)
X = bow.todense()
return [X,count_vect]
main.py
# -*- coding: utf-8 -*-
# ! /usr/bin/python
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.externals import joblib
import os.path
import nlp_tasks
from sklearn.neural_network import MLPClassifier # アルゴリズムとしてmlpを使用
def train():
classifier = MyMLPClassifier()
classifier.train('corpus.csv')
def predict():
classifier = MyMLPClassifier()
classifier.load_model()
result = classifier.predict(u"{カテゴリ判別したい記事内容}")
print(result)
class MyMLPClassifier():
model = None
model_name = "mlp"
def load_model(self):
if os.path.exists(self.get_model_path())==False:
raise Exception('no model file found!')
self.model = joblib.load(self.get_model_path())
self.classes = joblib.load(self.get_model_path('class')).tolist()
self.vectorizer = joblib.load(self.get_model_path('vect'))
self.le = joblib.load(self.get_model_path('le'))
def get_model_path(self,type='model'):
return 'models/'+self.model_name+"_"+type+'.pkl'
def get_vector(self,text):
return self.vectorizer.transform([text])
def train(self, csvfile):
df = pd.read_csv(csvfile,names=('text','category'))
X, vectorizer = nlp_tasks.get_vector_by_text_list(df["text"])
# loading labels
le = LabelEncoder()
le.fit(df['category'])
Y = le.transform(df['category'])
model = MLPClassifier(max_iter=300, hidden_layer_sizes=(100,),verbose=10,)
model.fit(X, Y)
# save models
joblib.dump(model, self.get_model_path())
joblib.dump(le.classes_, self.get_model_path("class"))
joblib.dump(vectorizer, self.get_model_path("vect"))
joblib.dump(le, self.get_model_path("le"))
self.model = model
self.classes = le.classes_.tolist()
self.vectorizer = vectorizer
def predict(self,query):
X = self.vectorizer.transform([query])
key = self.model.predict(X)
return self.classes[key[0]]
if __name__ == '__main__':
train()
#predict()
main.pyを実行すると、トレーニングが実行され、トレーニングが完了すると、dumpsのディレクトリ内に、モデル情報等が格納されます。
count_vect = CountVectorizer(analyzer=words)
ここでテキストを単語区切りのベクトルに変換するvectorizerを作成します。
analyzerというのは、テキストが入力された時、そのテキストを任意の方法で区切って返す関数を渡します。
今回の場合は_split_to_wordsという関数を用い、この関数内でmecabを使って形態素解析を行い、形態素毎に区切った配列を返すようにしています。
model = MLPClassifier(max_iter=300, hidden_layer_sizes=(100,),verbose=10,)
model.fit(X, Y)
ここが重要な部分で、ニューラルネットワークに入力(X)と正解ラベル(Y)を渡し、トレーニングを実行しています。
hidden_layer_sizesのパラメータによって、ニューラルネットワークの層とユニットの数をタブルにて定義します。
100unit ×2層の場合は、hidden_layer_sizes=(100,100)とします。
max_iterはトレーニングをどれだけ回すかというパラメータになり、多くするほど時間はかかるようになりますが、精度が上がっていきます。
また、一定の精度が出た時点でトレーニングは自動で止まるようになっています。
5-4. カテゴリ判別
トレーニングしたモデルを使って実際に新しいテストのカテゴリ判別をするには、一番最後の行のpredict()のコメントアウトを外し、train()をコメントアウトします。
下記の適当なニュース記事から本文を取ってきて、{カテゴリ判別したい記事内容}という箇所にコピペします。
実行すると、カテゴリが表示されるかと思います。期待のカテゴリになったでしょうか?
6. 発展編
上記のコードでカテゴリ分類は可能ですが、更に精度アップを目指したい方はこの先も読んで実行してみて下さい。
6-1. TfIdf
上記のコードでは、CountVectorizerというvectorizerを使っています。
これは、全ての単語において、出現するかしないかを01で表現したベクトルとなります。
ただ、実際カテゴリ判別をする際に「の」や「です」等は不要な気がしますね。これを考慮してくれるのがTfIdfです。
Tf = Term Frequency
Idf = Inverse Document Frequency
の略で、Tfはドキュメント内の単語の出現頻度、Idfは全ての文章内の単語の出現頻度の逆数です。
つまりTfIdfを使うと、いろいろな文章に出てくる単語は無視して、ある文章に何回も出てくる単語は重要な語として扱うというものです。
これを使うには、先程のコードを下記に変更します。
nlp_tasks.py
# -*- coding: utf-8 -*-
#! /usr/bin/python
import MeCab
from sklearn.feature_extraction.text import TfidfVectorizer
def _split_to_words(text):
tagger = MeCab.Tagger('-O wakati')
try:
res = tagger.parse(text.strip())
except:
return []
return res
def get_vector_by_text_list(_items):
count_vect = TfidfVectorizer(analyzer=_split_to_words)
bow = count_vect.fit_transform(_items)
X = bow.todense()
return [X,count_vect]
これだけで、TfIdfのベクトルを入力として使うことが可能です。
6-2. 交差検定
CountVectorizerやTfidfVectorizer、またMLPClassifierを扱ってきましたが、どのvectorizerがよいのか?
どのくらいのユニットの数にしたらいいのか等、実際の精度がわからないと決められないかと思います。
そこで交差検定という手法をつかい、どのパラメータ等がベストなのかを探ります。
MyMLPClassifierクラスに次のメソッドを追加します。
def cross_validation(self,csvfile):
self.model = MLPClassifier(max_iter=300, hidden_layer_sizes=(100,),verbose=10,)
df = pd.read_csv(csvfile,names=('text','category'))
_items = df["text"]
X, vectorizer = nlp_tasks.get_vector_by_text_list(_items)
# loading labels
le = LabelEncoder()
le.fit(df['category'])
Y = le.transform(df['category'])
scores = cross_val_score(self.model, X, Y, cv=4)
print(scores)
print(np.average(scores))
また、main.pyのtrain()の箇所をコメントアウトし、下記コードに書き換えます。
classifier = MyMLPClassifier()
classifier.cross_validation('corpus.csv')
cross_val_scoreというscikit-learnに元々入っている関数を呼んでいますが、ここで評価したいモデル、入力のベクトルX、出力ラベルY、データを何分割するかをcvのパラメータとして渡します。
コードではcv=4にしていますので、データを4分割して、3/4はトレーニングに使い、1/4は評価用のデータとして使い、評価用のデータの正解がどれくらいかというスコアを算出します。
そのため、scoresには配列で4つのスコアが返ってきます。
このスコアのバラ付きが少なく、平均が高いモデルが良いモデルということになります。
データによっても入力ベクトルの形式で最適な形式が変わってきたり、モデルのパラメータが変わってきますが、最初からそれを推定するのはとても困難です。
例えば、MLPClassifierの隠れ層の最適なサイズは最初から分かる人は殆どいないと思いますので、いくつか試す必要があります。
機械的に色々なパラメータを試す方法は、scikit-learn(機械学習)の推定器:Estimatorの選び方 に載っていますので、こちらも参考にしてみてください。