1. 弊社分析の特徴
構造データ(数値、カテゴリなど)、非構造データ(テキスト)の両方が分析対象と出来ます。(他社様は、非構造データのみ対象のところが多いかと思います。)
構造データでは、どのような変数が合格に影響しているかの分析が可能です。
また、テキスト解析では、テキストから得られる情報(主体性、コミュニケーション能力など)を可視化します。
2. AIを用いて可視化できるアウトプット
2-1. 合格・辞退スコア

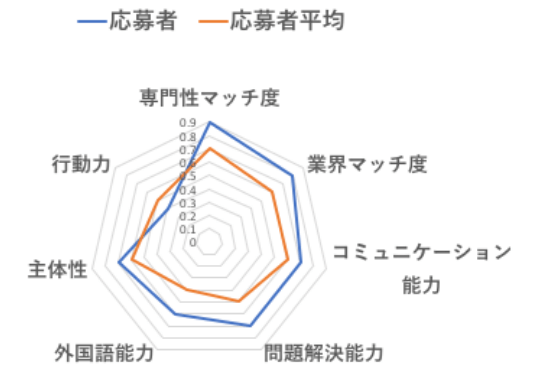
2-2. 応募者の適性可視化
例
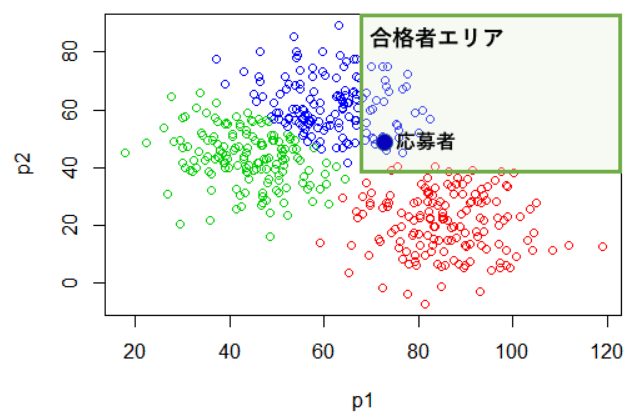
2-3. 応募者クラスター
応募者クラスターと合格ライン、p1・p2は適性項目の合成変数、色分けはクラスターの種類
2-4. 導入前・導入後 選考作業 削減量
内定承諾率、ひとりあたりの選考にかかる作業の削減量
3. 学習データ
3-1. 必要情報
- 300人分程度のエントリーシート(過去データは多いほど望ましい)
- 合格情報(内定:あり・なし)
- テキスト解析の教師データ(主体性、コミュニケーション能力に関する人間による5段階評価値)がデータとしてある(部分サンプルでも可能・できれば300人分程度以上)
3-2. 追加情報
あるとより望ましいデータ
- 辞退あり・なし(辞退スコアが必要な場合)
- 従来選考の過程で重視しているポイントに関してのコメント:診断項目の検討に使用
- 導入前後で導入効果を測定できるKPI項目(応募者数、内定者数、内定承諾者数、選考に要する人員数、単位作業量(一人あたりの平均作業時間)など)
- 競合他社ランクなどの補助的なデータ
3-3. エントリーシートより特徴量として使用する項目
例
| スコア大分類 | 診断項目 | 変数名 | 変数タイプ |
|---|---|---|---|
| 合格率 | 合格率 | 内定有無 | カテゴリ変数 |
| その他各種変数 | – | ||
| 辞退確率 | 辞退確率 | 辞退有無 | カテゴリ変数 |
| 訪問動機 | カテゴリ変数 | ||
| 他社ランク | 量的変数 | ||
| 当社志望順位 | 量的変数 | ||
| 相談相手 | カテゴリ変数 | ||
| インターン | 量的変数 | ||
| 説明会 | 量的変数 | ||
| 面接 | 量的変数 | ||
| 推薦応募有無 | 量的変数 | ||
| 適性 | 専門性マッチ度 | 学部 | カテゴリ変数 |
| 得意科目 | カテゴリ変数 | ||
| 興味のある職種 | カテゴリ変数 | ||
| 卒論テーマ | テキスト | ||
| 業界マッチ度 | 興味のある業界 | カテゴリ変数 | |
| 会社選定ポイント | カテゴリ変数 | ||
| 興味のある点 | カテゴリ変数 | ||
| コミュニケーション能力 | 質問(特徴量A) | テキスト | |
| 経験(特徴量A) | テキスト | ||
| 大学時代(特徴量A) | テキスト | ||
| 問題解決能力 | 年齢 | 量的変数 | |
| 大学学部ランク | 量的変数 | ||
| 外国語能力 | TOEIC | 量的変数 | |
| 主体性 | 質問(特徴量B) | テキスト | |
| 経験(特徴量B) | テキスト | ||
| 大学時代(特徴量B) | テキスト | ||
| 行動力 | 部活・サークル活動 | カテゴリ変数 | |
| アルバイト経験 | カテゴリ変数 | ||
| アルバイト年数 | 量的変数 |
無料相談・お問合せ
お電話、または下記フォームからお気軽にお問合せ下さい。
お電話
03-4405-4347 (平日 9:00 – 17:30)
フォーム